












Comment nous avons économisé 98 % des coûts du cloud en écrivant notre propre base de données, par Hivekit
Quelle est la première règle en programmation ? Peut-être quelque chose comme "ne vous répétez pas" ou "si ça marche, n'y touchez pas" ? Ou encore "n'écrivez pas votre propre base de données"... C'est en effet une bonne règle.
Les bases de données sont un cauchemar à écrire, des exigences en matière d'atomicité, de cohérence, d'isolation et de durabilité (ACID) au partage, en passant par la récupération des erreurs et l'administration, tout est d'une difficulté inouïe.
Heureusement, il existe des bases de données extraordinaires qui ont été perfectionnées pendant des décennies et qui ne coûtent pas un centime. Alors pourquoi diable serions-nous assez fous pour en écrire une à partir de zéro ?
Eh bien, voici ce qu'il en est...
Hivekit exploite une plateforme cloud qui suit des dizaines de milliers de personnes et de véhicules en même temps. Chaque mise à jour de localisation est stockée et peut être récupérée via une API d'historique.
Le nombre de véhicules connectés simultanément et la fréquence de leurs mises à jour de localisation varient considérablement dans le temps, mais avoir environ 13 000 connexions simultanées, chacune envoyant environ une mise à jour par seconde, est assez normal.
Les clients de Hivekit utilisent ces données de manières très différentes. Certains cas d'utilisation sont très grossiers, par exemple lorsqu'une société de location de voitures souhaite afficher un aperçu de l'itinéraire emprunté par un client au cours de la journée. Ce type d'exigence pourrait être traité avec 30 à 100 points de localisation pour un trajet d'une heure, ce qui permettrait d'agréger et de compresser fortement les données de localisation avant de les stocker.
Mais il existe de nombreux autres cas d'utilisation pour lesquels cette option n'est pas envisageable. Les entreprises de livraison qui veulent pouvoir rejouer les secondes exactes qui ont précédé un accident. Les mines dotées de systèmes de localisation très précis sur site qui souhaitent générer des rapports indiquant quel travailleur a pénétré dans telle ou telle zone restreinte - à un demi-mètre près.
Ainsi, étant donné que le niveau de granularité dont chaque client aura besoin n'est pas connu à l'avance, chaque mise à jour de l'emplacement est stockée. Avec 13 000 véhicules, cela représente 3,5 milliards de mises à jour par mois, et ce chiffre ne fera qu'augmenter. Jusqu'à présent, Hivekit a utilisé AWS Aurora avec l'extension PostGIS pour le stockage des données géospatiales. Mais Aurora coûte déjà plus de 10 000 dollars par mois, rien que pour la base de données, et ce coût ne fera qu'augmenter à l'avenir.
Mais il ne s'agit pas seulement du prix d'Aurora. Bien qu'Aurora résiste assez bien à la charge, beaucoup des clients de Hivekit utilisent la version sur site de l'application. Et là, ils doivent faire tourner leurs propres clusters de base de données qui sont facilement submergés par ce volume de mises à jour.
Pourquoi n'utilisons-nous pas une base de données spécialement conçue pour les données géospatiales ?
Malheureusement, cela n'existe pas. De nombreuses bases de données, de Mongo et H2 à Redis, prennent en charge les types de données spatiales comme les points et les zones. Il existe également des "bases de données spatiales", mais il s'agit exclusivement d'extensions qui se greffent sur les bases de données existantes. PostGIS, construit au-dessus de PostgreSQL est probablement le plus connu, mais il y en a d'autres comme Geomesa qui offrent d'excellentes capacités d'interrogation géospatiale au-dessus d'autres moteurs de stockage.
Malheureusement, ce n'est pas ce dont nous avons besoin.
Voici à quoi ressemble notre profil d'exigences :
- Performances d'écriture extrêmement élevées : nous voulons être en mesure de gérer jusqu'à 30 000 mises à jour de localisation par seconde et par nud. Elles peuvent être mises en mémoire tampon avant d'être écrites, ce qui permet de réduire considérablement le nombre d'IOPS.
- Parallélisme illimité : plusieurs nuds doivent être en mesure d'écrire des données simultanément, sans limite supérieure.
- Petite taille sur le disque : Compte tenu du volume de données, nous devons veiller à ce qu'elles occupent le moins d'espace possible sur le disque.
Cela signifie que nous devrons accepter certains compromis. Voici ce que nous acceptons :
- Des performances modérées pour les lectures sur disque : Notre serveur est construit autour d'une architecture en mémoire. Les requêtes et les filtres pour les flux en temps réel sont exécutés sur des données en mémoire et sont donc très rapides. Les lectures sur disque n'ont lieu que lorsqu'un nouveau serveur est mis en ligne, lorsqu'un client utilise l'API d'historique ou (bientôt) lorsqu'un utilisateur de l'application remonte le temps sur notre interface de jumeau numérique. Ces lectures sur disque doivent être suffisamment rapides pour garantir une bonne expérience utilisateur, mais elles sont comparativement peu fréquentes et de faible volume.
- De faibles garanties de cohérence : Nous acceptons de perdre quelques données. Nous mettons en mémoire tampon environ une seconde de mises à jour avant d'écrire sur le disque. Dans les rares cas où un serveur tombe en panne et qu'un autre prend le relais, nous acceptons de perdre cette seconde de mises à jour de l'emplacement dans la mémoire tampon actuelle.
Quel type de données devons-nous stocker ?
Le principal type d'entité que nous devons conserver est un "objet", c'est-à-dire un véhicule, une personne, un capteur ou une machine. Les objets ont une étiquette d'identification, un emplacement et des données clés/valeurs arbitraires, par exemple pour les niveaux de carburant ou l'identification du conducteur actuel. Les emplacements comprennent la longitude, la précision de la latitude, la vitesse, le cap, l'altitude et la précision de l'altitude - bien que chaque mise à jour ne puisse modifier qu'un sous-ensemble de ces champs.
En outre, nous devons également stocker des zones, des tâches (quelque chose qu'un "objet" doit faire) et des instructions (de minuscules éléments de logique spatiale que le serveur hivekit exécute sur la base des données entrantes).
Ce que nous avons construit
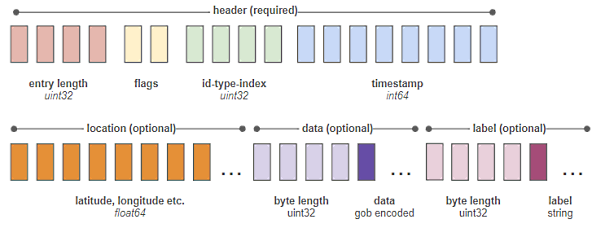
Nous avons créé un moteur de stockage en cours de processus qui fait partie du même exécutable que notre serveur principal. Il écrit un format binaire minimal, basé sur le delta. Une seule entrée ressemble à ceci :
Chaque bloc représente un octet. Les deux octets étiquetés "flags" sont une liste de commutateurs oui/non qui spécifient "has latitude", "has longitude", "has data", etc. - indiquant à notre analyseur syntaxique ce qu'il doit rechercher dans les octets restants de l'entrée.
Nous stockons l'état complet d'un objet toutes les 200 écritures. Entre ces écritures, nous ne stockons que les deltas. Cela signifie qu'une simple mise à jour de l'emplacement, avec l'heure et l'identifiant, la latitude et la longitude, ne prend que 34 octets. Cela signifie que nous pouvons stocker environ 30 millions de mises à jour de localisation dans un gigaoctet d'espace disque.
Nous maintenons également un fichier d'index séparé qui traduit la chaîne statique d'identification de chaque entrée et son type (objet, zone, etc.) en un identifiant unique de 4 octets. Comme nous savons que cet identifiant de taille fixe correspond toujours aux octets 6 à 9 de chaque entrée, l'extraction de l'historique d'un objet spécifique est extrêmement rapide.
Le résultat : Une réduction de 98 % du coût du cloud et une plus grande rapidité
Ce moteur de stockage fait partie de notre serveur binaire, le coût de son fonctionnement n'a donc pas changé. Ce qui a changé en revanche, c'est que nous avons remplacé nos instances Aurora à 10 000 $/mois par un volume Elastic Block Storage (EBS) à 200 $/mois. Nous utilisons des disques SSD Provisioned IOPS (io2) avec 3000 IOPS et nous mettons en lot les mises à jour à raison d'une écriture par seconde par nud et par domaine.
EBS intègre des sauvegardes et des restaurations automatisées, ainsi que des garanties de disponibilité élevées, de sorte que nous n'avons pas l'impression d'avoir manqué l'une des garanties de fiabilité offertes par Aurora. Nous produisons actuellement environ 100 Go de données par mois. Mais comme les clients interrogent rarement des entrées datant de plus de 10 jours, nous avons commencé à transférer toutes les données de plus de 30 Go vers AWS Glacier, ce qui nous permet de réduire encore nos coûts EBS.
Mais il n'y a pas que le coût. L'écriture sur un EBS local via le système de fichiers est beaucoup plus rapide et a moins de frais généraux que l'écriture sur Aurora. Les requêtes sont également beaucoup plus rapides. C'est difficile à quantifier car les requêtes ne sont pas exactement analogues, mais par exemple, la recréation d'un point particulier dans l'historique d'un domaine est passée d'environ deux secondes à environ 13 ms.
Bien sûr, c'est une comparaison inéquitable, après tout, Postgres est une base de données généraliste avec un langage de requête expressif et ce que nous avons construit est juste un curseur qui lit un flux de fichiers binaires avec un ensemble très limité de fonctionnalités - mais encore une fois, c'est la fonctionnalité exacte dont nous avons besoin et nous n'avons pas perdu d'autres fonctionnalités.
Hivekit fournit une API évolutive permettant de suivre des millions de personnes, de véhicules et de machines, de diffuser des localisations en temps réel vers des tableaux de bord et des appareils d'utilisateurs finaux, de conserver un historique détaillé des itinéraires et d'exécuter une logique spatiale - le tout étant entièrement intégré à l'application mobile et à l'interface utilisateur de Hivekit. Pour en savoir plus sur l'API et les fonctionnalités de Hivekit, consultez le site https://hivekit.io/developers/.
À propos de Hivekit
Hivekit, fondée en 2023, est le résultat de cinq années de recherche et de développement visant à créer un nouveau mode de coordination de la main-d'uvre basé sur l'auto-organisation émergente présentée par les essaims. Aujourd'hui, Hivekit propose une plateforme d'orchestration de données géospatiales et de main-d'uvre qui permet aux opérateurs de suivre les véhicules, les personnes, les machines et les sources de données, d'émettre des commandes manuelles et de suivre leur exécution, ainsi que de créer des règles comportementales qui exécutent des opérations complexes en pilotage automatique. Hivekit est une entreprise distribuée dont le siège se trouve aux États-Unis et dont les effectifs sont répartis entre l'Allemagne et le Royaume-Uni.
Source : "How weve saved 98% in cloud costs by writing our own database" (Hivekit)
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :
 Répondre avec citation
Répondre avec citation









Partager