

 zlib est une bibliothèque de compression très largement utilisée dans bon nombre dapplications : les consoles de jeu les plus récentes (PlayStation 3 et 4, Xbox 360 et One, notamment), mais aussi le noyau Linux, les systèmes de gestion des versions comme SVN ou Git ou le format dimage PNG. Sa première version publique a été publiée en 1995 par Jean-Loup Gailly et Mark Adler en implémentant la technique DEFLATE. Son succès est notamment dû à labsence de brevets logiciels (ce qui a principalement un intérêt aux États-Unis) sur ses algorithmes, mais aussi à des débits en compression et décompression relativement élevés pour une utilisation en ressources assez faible et un bon taux de compression.
zlib est une bibliothèque de compression très largement utilisée dans bon nombre dapplications : les consoles de jeu les plus récentes (PlayStation 3 et 4, Xbox 360 et One, notamment), mais aussi le noyau Linux, les systèmes de gestion des versions comme SVN ou Git ou le format dimage PNG. Sa première version publique a été publiée en 1995 par Jean-Loup Gailly et Mark Adler en implémentant la technique DEFLATE. Son succès est notamment dû à labsence de brevets logiciels (ce qui a principalement un intérêt aux États-Unis) sur ses algorithmes, mais aussi à des débits en compression et décompression relativement élevés pour une utilisation en ressources assez faible et un bon taux de compression.Fonctionnement de zlib
Au niveau algorithmique, DEFLATE utilise des techniques éprouvées des années 1990, principalement un dictionnaire (selon lalgorithme LZ77) et un codage de Huffman. Le principe dun dictionnaire est de trouver des séquences de mots répétées dans le fichier à compresser et de les remplacer par un index dans un dictionnaire. Le codage de Huffman fonctionne avec un arbre pour associer des codes courts à des séquences de bits très fréquentes. Ces deux techniques sassocient pour former la technique de compression standard actuelle.
Concurrents modernes
Cependant, depuis le développement de ces techniques, la recherche au niveau de la compression sans perte a fait de grands progrès. Par exemple, LZMA (lalgorithme derrière 7-Zip et XZ) exploite des idées similaires (plus la probabilité de retrouver des suites de bits dans le fichier à compresser, plus la manière compressée de lécrire doit être courte), mais avec une dépendance entre différentes séquences de bits (chaîne de Markov), ainsi quun codage arithmétique. Le résultat est un taux de compression souvent bien meilleur que DEFLATE, mais le processus de compression est bien plus lent, tout en gardant une décompression rapide et sans besoins extravagants en mémoire. LZHAM est aussi basé sur les mêmes principes avec des améliorations plus modernes et vise principalement une bonne vitesse de décompression (au détriment de la compression).
Cependant, pour un usage plus courant, les débits en compression et décompression sont aussi importants lun que lautre, avec un aussi bon taux de compression que possible. Par exemple, pour des pages Web dun site dynamique, le serveur doit compresser chaque page indépendamment, puisque le contenu varie dun utilisateur à lautre. Plusieurs bibliothèques de compression sont en lice, comme LZ4 (qui se propose comme une bibliothèque très généraliste, comme zlib, mais très rapide en compression et décompression), Brotli (proposé par Google pour un usage sur le Web) ou encore BitKnit (proposé par RAD pour la compression de paquets réseau cette bibliothèque est la seule non libre dans cette courte liste). Ces deux dernières se distinguent par leur âge : elles ont toutes deux été annoncées en janvier 2016, ce qui est très récent.
Une première comparaison concerne la quantité de code de chacune de ces bibliothèques : avec les années, zlib a accumulé pas loin de vingt-cinq mille lignes de code (dont trois mille en assembleur), largement dépassé par Brotli (pas loin de cinquante mille lignes, dont une bonne partie de tables précalculées). Les deux derniers, en comparaison, sont très petits : trois mille lignes pour LZ4 ou deux mille sept cents pour BitKnit (en incluant les commentaires, contrairement aux autres !).
Tentative de comparaison
Rich Geldreich, spécialiste de la compression sans perte et développeur de LZHAM, propose une méthodologie pour comparer ces bibliothèques : au lieu dutiliser un jeu de données standard, mais sans grande variété (comme un extrait de Wikipedia, cest-à-dire du texte en anglais sous la forme de XML), il propose un corpus de plusieurs milliers de fichiers (ce qui na rien de nouveau, Squash procédant de la même manière) et présente les résultats de manière graphique. Cette visualisation donne un autre aperçu des différentes bibliothèques.
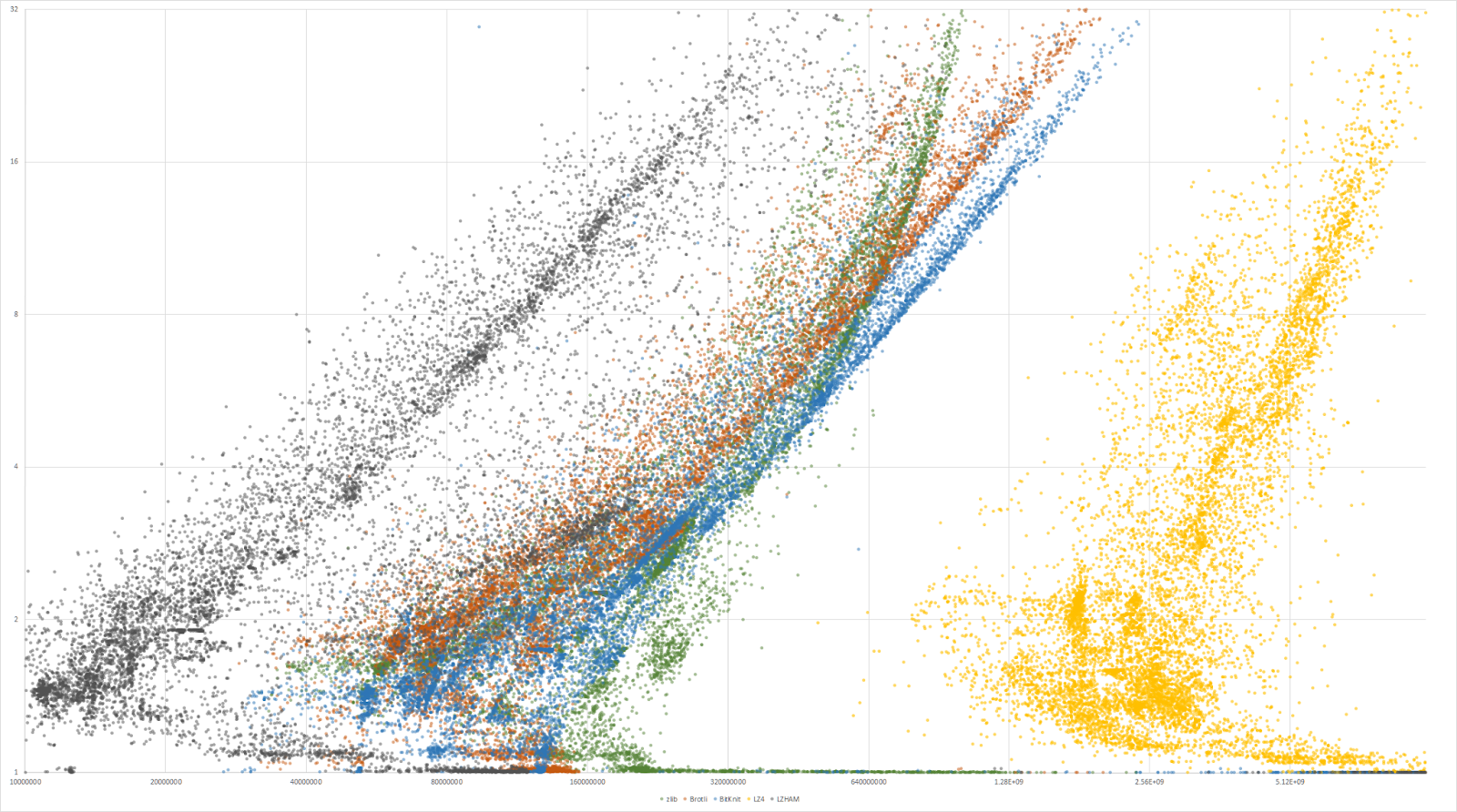
Deux nuages de points sortent du lot : LZ4, tout à droite, est extrêmement rapide en décompression, tout lopposé de LZHAM, qui propose néanmoins de bien meilleurs taux de compression. zlib montre un comportement assez étrange : le débit de décompression naugmente plus à partir dun certain point, contrairement aux autres bibliothèques. Lauteur propose des comparaisons plus spécifiques des taux de compression de chaque bibliothèque en fonction des fichiers.
Et donc ?
Cette comparaison montre que les différentes bibliothèques ne sont pas toujours meilleures les unes que les autres, tout dépend du contenu du fichier, de sa taille, des ressemblances par rapport aux estimations des concepteurs (plus particulièrement dans le cas dalgorithmes qui ne sadaptent pas dynamiquement au contenu et préfèrent utiliser des tables prédéfinies, ce qui évite de transmettre une série dinformations).
Notamment, Brotli est prévu pour le Web : il fonctionne particulièrement bien sur des données textuelles. Tout comme zlib, il utilise des tables précalculées, ce qui lui donne un avantage sur des fichiers plus petits. Au contraire, BitKnit fonctionne très bien sur du contenu binaire, bien plus courant pour les données de jeux vidéo. Ces deux bibliothèques ont donc chacune leurs points forts selon les domaines dapplication prévus et y sont meilleures que zlib.
Source : zlib in serious danger of becoming obsolete.
Ce contenu a été publié dans Informatique théorique et algorithmique par dourouc05.
Vous avez lu gratuitement 10 728 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.


