

 Que devons-nous privilégier dans la rédaction de notre code ? La vitesse ou la qualité ?
Que devons-nous privilégier dans la rédaction de notre code ? La vitesse ou la qualité ? Étude du cas de Facebook
Si ces deux notions sont importantes, laquelle doit primer ? Pour le développeur Graham King, la qualité semble être le facteur le plus important. Il essaye de le montrer en donnant trois éléments qui le conduisent à penser que Facebook a des problèmes dans la qualité de son code. « Je ne travaille ni chez Facebook ni chez la concurrence. Je suis juste un observateur », précise-t-il.
Élément numéro 1 : « iOS ne peut pas gérer notre taille »
Il y a près dun mois, Simon Whitetaker, ingénieur logiciel Facebook à Londres, a fait la présentation « iOS at Facebook » qui parlait de lapplication Facebook sur lécosystème iOS. Il était notamment question dexpliquer la raison pour laquelle Facebook se trouvait être volumineux chez les utilisateurs des iDevices et il avançait que « il y a plus de 18 000 classes dans lapplication ( ) raison pour laquelle lapplication binaire elle-même fait plus de 114 Mo ».
Après avoir rappelé que lapplication Facebook sur la plateforme iOS a plus de 18 000 classes Objective-C, King a précisé quen une seule semaine 429 personnes y ont contribué : « cest-à-dire que 429 personnes ont en quelque sorte travaillé sur lapplication iOS de Facebook. Au lieu de réaliser lévidence qui veut quil y ait eu trop de personnes qui ont travaillé sur cette application, la présentation blâme tout, du git jusquau Xcode, pour ces 18 000 classes ».
Dailleurs un commentaire de lutilisateur ChadBan sur Reddit le résume assez bien : « tout ce à quoi je peux penser quand je lis ça cest à Design Stamina Hypothesis de Martin Fowler sur ce qui arrive sur un système sans architecture. Il devient plus difficile et cela prend plus de temps dajouter de nouvelles fonctionnalités contrairement à un système pour lequel larchitecture est dor. La solution de Facebook pour une courbe en baisse semble de balancer plus de développeurs dessus jusquà ce quelle se plie vers lorientation désirée. Je ne voudrais pas que qui que ce soit dans ma petite équipe pense cest ce que les enfants cool font. Je ne voudrais pas avoir à travailler de cette façon, même si elle marche pour eux ».
Élément numéro 2 : peut-être penser à lutilisation des RAMDisk ?
En juin de lannée 2014, les ingénieurs Facebook ont publié un article intitulé « Fast Database Restarts at Facebook » qui parlait du redémarrage des serveurs quils utilisent en étudiant le cas du plus rapide dentre eux : Scuba. Si King sy est intéressé, cest en particulier parce que dans le synopsis, les ingénieurs ont noté que « notre principale observation est que nous pouvons dissocier la durée de vie de la mémoire de la durée de vie du processus ».
King rappelle que lidée est semblable à la sauvegarde des données dans la mémoire cache distribuée ou dans Redis, le système de gestion de bases de données clef-valeur scalable, puis redémarrer votre processus et enfin aller récupérer les données que vous avez sauvegardées, la seule différence étant quils gardent les données dans la mémoire partagée au lieu de Memcached ou Redis. « La partie de la mémoire partagée est juste un leurre, mais il faut lire larticle jusquà la conclusion pour le comprendre », avance-t-il.
Ils maintenaient déjà les données sur le disque entre les redémarrages, mais la recharge à partir des disques étaient trop lente : « la lecture de près de 120 Go de données sur le disque prend entre 20 et 25 minutes, la lecture de ces données dans leur format disque et les convertir dans le format en mémoire peut prendre 2,5 ou 3 heures », ont expliqué les ingénieurs. Le disque ne les ralentit pas, cest plutôt le format de conversion comme le montre la conclusion : « la conversion du format disque pour le format mémoire est une surcharge de récupération importante. Nous envisageons dutiliser le format de la mémoire partagée décrite dans ce document comme étant le format du disque ». Aussi, King précise que ce quils ont fait cest décrire un nouveau code pour sauvegarder/recharger qui fonctionne avec la mémoire partagée avec son propre nouveau format de conversion.
« Si vous avez lu Kerrisk, vous remarquerez à la page 275 (section 14.10) que la mémoire partagée sur Linux est implémentée avec le système de fichiers tmpfs et tempfs est la façon dont Linux fait des disques virtuels, qui « ne consomment quautant de mémoire et despace déchange quactuellement requis par les fichiers quils détiennent » précise King.
Aussi, si vos routines de conversion de format de sauvegarde sur le disque ralentissent votre code, que vous deviez avoir à les réécrire de toutes les façons et que vous vouliez « dissocier la durée de vie de la mémoire de la durée de vie du processus », ne préféreriez-vous pas juste écrire vos fichiers de disque sur un disque virtuel ? Ils ont sans nul doute dû le remarquer, mais alors il devait être trop tard, ils devaient avancer rapidement et publier des choses ».
Élément numéro 3 : notre site fonctionne quand nos ingénieurs vont en vacances
« Étant donné que Facebook encourage ses ingénieurs dans la philosophie Move Fast And Break Things, il est aisé de sattendre à plusieurs erreurs dorigine humaine. Nos données suggèrent que lerreur humaine est un facteur de nos échecs. La figure 1 comprend des données issues dune analyse de la chronologie des évènements suffisamment sévère pour être considérées comme étant une violation SLA. Chaque violation indique une instance où nos objectifs de fiabilité interne nont pas été atteints et ont provoqué la génération dune alerte. Parce que nos objectifs sont stricts, la plupart de ces incidents sont mineurs et ne vont pas causer de changements perceptibles par lutilisateur », va rapporter Fail at Scale.
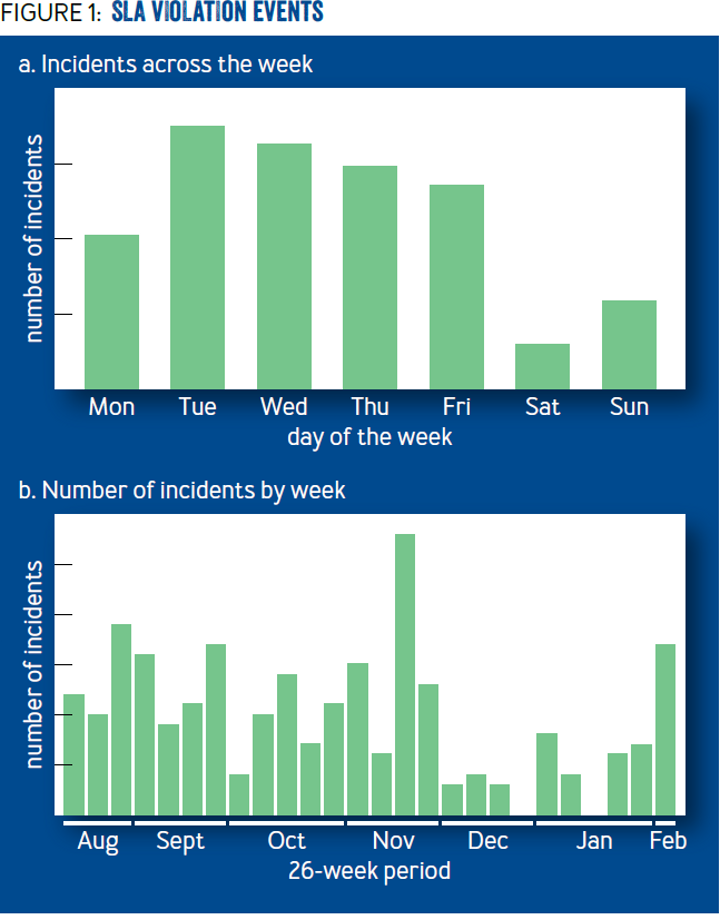
« La figure 1a montre comment les incidents se sont beaucoup moins produits le samedi et le dimanche, même si le trafic est resté consistant tout au long de la semaine. La figure 2b montre une période de six mois durant laquelle seules deux semaines nont pas enregistré dincidents, notamment la semaine de Noël et la semaine où les employés sont tenus de faire des peer reviews ».
Pour King, malgré le succès de Facebook, ses ingénieurs talentueux, ses ressources illimitées, le réseau social a quand même de grosses difficultés avec la qualité du code. Il tire donc deux leçons :
- la culture de lentreprise importe : la culture qui veut que les employés suivent la philosophie « Move Fast And Break Things » qui fait que les développeurs se concentrent difficilement sur la qualité ;
- la qualité importe : étant donné que si vous ne vous concentrez pas sur la qualité, cela pourrait se faire à vos dépens. Tout dabord parce que faire des changements, aussi petits soient-ils, pourrait savérer très pénible, mais également parce que les publications pourraient provoquer des bogues parce que vous ne comprendrez plus suffisamment bien les relations.
Quoi quil en soit, en avril 2014, lors de la conférence F8, le PDG de Facebook a fait évoluer la philosophie « Move Fast and Break Things » qui est devenue « Move Fast With Stable Infra ». Il a expliqué que « nous avons utilisé ce fameux mantra et lidée était quen tant que développeurs, être rapides était si important que nous étions même prêts à tolérer quelques bogues mineurs pour y parvenir. Ce que nous avons réalisé avec le temps cest que cela ne nous aidait pas à être rapides parce que nous devions ralentir pour corriger ces bogues, et cela naméliorait en rien notre vitesse ».

Source : billet de blog Graham King, Simon Whitaker, Fast Database Restarts at Facebook, Fail at Scale
Et vous ?
 Que pensez-vous des arguments qu'il a avancés ? Pensez-vous qu'ils suffisent pour pouvoir parler d'un problème dans la qualité du code de Facebook ? Partagez-vous son avis ? De la vitesse et de la qualité, quel est le paramètre à privilégier ? Pourquoi ?
Que pensez-vous des arguments qu'il a avancés ? Pensez-vous qu'ils suffisent pour pouvoir parler d'un problème dans la qualité du code de Facebook ? Partagez-vous son avis ? De la vitesse et de la qualité, quel est le paramètre à privilégier ? Pourquoi ?
Vous avez lu gratuitement 4 874 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.




