
Envoyé par
Stéphane le calme

Pour faire valoir les bénéfices dune telle stratégie, elle a évoqué sa propre expérience : « jai débuté ma carrière dans lindustrie du jeu vidéo où jai travaillé comme développeur logiciel pendant plusieurs années. Et, à cette période, lentreprise pour laquelle je travaillais avait lhabitude de bosser sur plusieurs jeux vidéo au même moment et chaque jeu était sur son propre dépôt. Il arrivait souvent que ces jeux soient conçus à partir des mêmes moteurs. Aussi, nous avions une copie du code du moteur dun jeu dans chacun de nos dépôts ». Si ces jeux allaient évoluer de manière indépendante, certains managers ont décidé que dans le cas où une fonctionnalité devait être implémentée dans un code base devait également être portée dans les autres. Elle a qualifié ce processus de difficile.
Je pensais pas que le
"feature branching" et le
"release branching" était si peu connu. Surtout de la part de quelqu'un travaillant chez Google ...
Envoyé par
Stéphane le calme
Qu'en pensez-vous ?
Je pense qu'on manque de beaucoup d'informations. Parce que décrit comme cela, ce n'est pas viable :
Envoyé par
Stéphane le calme
un historique de 35 millions de modifications (45 000 par jour en moyenne 15 000 effectués par des humains, 30 000 par des systèmes automatisés)
Les gens passent leur temps à faire des merges ???
Envoyé par
Stéphane le calme
Un versioning unifié
Si je fais une nouvelle release d'un projet, je suis obligé de prendre la dernière version de mes dépendantes ???
Envoyé par
Stéphane le calme
Un partage et une réutilisation extensifs du code
Quelle différence avec une gestion de configuration des binaires ??? Ou une indexation des sources ???
Envoyé par
Stéphane le calme
Une gestion simplifiée de la dépendance
Idem ??? Ou est la simplicité si tout impact d'une dépendance impactent mon projet ???
Envoyé par
Stéphane le calme
Des changements au niveau atomique
Je vois pas trop l'avantage ??? Toute modification doit être gérée globalement ou pas du tout ???
Envoyé par
Stéphane le calme
Une collaboration entre les équipes
D'expérience moins les groupes dépendent les uns des autres, mieux c'est ???
Envoyé par
Stéphane le calme
Une visibilité du code et une arborescence claire qui fournissent un espace de noms implicite déquipe.
Parce que rechercher dans "1 milliard de fichiers, 9 millions de fichiers source, 2 milliards de ligne de code, un historique de 35 millions de modifications [...] pour un poids total de 86 Téraoctets", il ne faut pas indexer ??? Parce qu'une unique arborescence c'est le seul moyen d'organiser et le plus efficace (cf. catégorisation, mot clé, etc.) ???
Envoyé par
Stéphane le calme
En conclusion, Google estime que ce modèle de gestion de source marche bien lorsquil est accompagné dune culture dingénierie de transparence et de collaboration. Si Google a beaucoup investi sur les outils dévolutivité et de productivité afin de soutenir ce modèle à cause des avantages significatifs quil en retire, lentreprise reconnaît que cette approche pourrait ou pas être la meilleure approche pour votre entreprise.
Je pense que s'ils avaient adopté une autre approche avec le même investissement dans les outils. Le résultat aurait été similaire. Il serait intéressant qu'il compare leur modèle avec d'autres en supposant la même qualité d'outillage ...
Envoyé par
Stéphane le calme
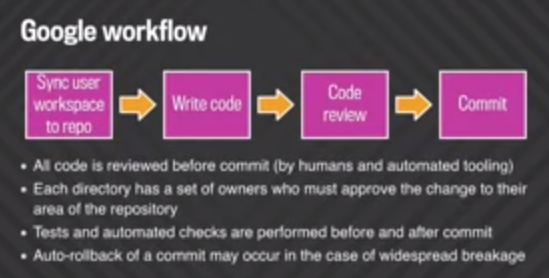
Lentreprise a également présenté son workflow. Le code est dabord examiné avant dêtre porté dans le dépôt (par des humains ou des outils automatisés). Chaque fichier a un ensemble de propriétaires qui doivent approuver les changements effectués dans leur zone sur le dépôt. Des tests et des vérifications automatisées sont effectués avant et après le portage. Une restauration automatique dune modification pourrait arriver en cas de plantage généralisé.
Ce que je crois en comprendre c'est qu'il existe une méga-branche principale mais que chaque "groupe de projet" dispose d'une branche qui est un assemblage/vue de différents répertoires "tiers" aux versions souhaitées. Un peu comme on le peut le faire avec les
"external" réflexifs de SVN ou les VOBs de ClearCase. On peut également avoir le même fonctionnement avec CVS mais cela demande une certaine organisation. On pourrait également atteindre le même objectif avec Git mais il n'est pas possible de référencer un groupe de fichiers (ie répertoire) par un hash comme on le fait avec un commit (à ma connaissance).
En résumé, ils font la gestion de configuration au niveau du source et non du binaire. Je vois qu'un intérêt moyen (mais non nul) surtout devant une telle quantité.
Envoyé par
DonQuiche
"Partager et réutiliser" ne veut pas dire "créer des dépendances inutiles". Cela veut simplement dire que si quelqu'un a besoin d'un code pour une tâche précise, il peut aisément chercher dans toute la base de Google et recopier un code dont il sait qu'il est de qualité, testé et sans problèmes de licences. C'est une bonne pratique.
Si c'est pour recopier, pas besoin d'un gros dépôt de source. Juste d'une bonne indexation.
Envoyé par
DonQuiche
Et il est toujours mieux de ne pas avoir besoin d'outils supplémentaire, de ne pas perdre de temps avec, de ne pas avoir besoin de former des employés à cela.
Leurs outils sont des outils supplémentaires auxquels il faut former les employés. Qui de plus venant d'autres horizons devront désapprendre les
standards que sont Maven/Ivy, Setuptools/Pip, etc.
Envoyé par
DonQuiche
Si tu veux modifier le projet XYZ, il te suffit d'ouvrir le repo et de chercher le dossier racine "XYZ". C'est quand même plus sympa que de faire un "ls" pour voir une liste de dossiers ayant les noms d'équipes dont tu ne sais pas qui elles sont et ce qu'elles font. Avec leur système pas besoin de savoir qui est propriétaire de "XYZ", ce qui permet aussi de pouvoir distribuer ou transférer la propriété d'un projet.
Tu fais un "ls" sur "1 milliard de fichiers pour un poids total de 86 Téraoctets" ?
Envoyé par
DonQuiche
Au lieu d'avoir une liste de repos ayant les noms d'équipes dont tu ne sais pas qui elles sont et ce qu'elles font, tu as une liste de projets.
Je connais pas d'organisation qui nomme ces dépôts avec le nom des équipes.
Envoyé par
DonQuiche
Tu as mal compris ce qu'ils veulent dire :
a) Tout le monde peut intervenir sur tout (si tu découvres un bug dans X tu peux directement soumettre une pull request plutôt qu'un rapport de bug)
b) Certains projets n'ont pas (plus) d'équipe dédiée mais sont utilisés et modifiés par plusieurs équipes. Et une équipe peut temporairement s'approprier le contrôle d'un projet commun.
Le second point est un modèle intéressant pour certaines infrastructures communes à la boîte, même si je présume qu'ils conservent un ou des référents qui font autorité.
C'est quoi la différence avec N dépôts ?
Envoyé par
DonQuiche
Je ne vois pas en quoi c'est un problème. C'est un maigre sacrifice nécessaire, aisément remplacé par des numéros de build serveur, des dates de build ou des versons publiques.
Cela signifie que tu colles la même étiquette pour tous tes projets. A moins de tous les livrer en même temps, cela n'a pas pas beaucoup de sens.
Envoyé par
DonQuiche
Sauf que certains projets sont intimement liés (micro-services par ex) et que pour cette raison une même équipe utilise un repo commun plutôt qu'un repo par projet. Dans ce cas-là les repos portent le nom de l'équipe. Ou le nom d'un super-projet. Dans tous les cas cela complique la visibilité pour une personne extérieure.
Le principe des micro-services c'est justement de rendre de l'indépendance à des composants. Rien n'empêche d'être intelligent et de créer des dépôts séparés mais avec un préfixe si c'est le besoin. Ne compare pas une organisation sainement choisi avec une autre complètement inappropriée. De toutes façons chercher dans 86 dépôts de 1To chacun ou dans 1 dépot de 86To, tu pourras jamais tout faire tenir sur ton poste de travail.
Envoyé par
DonQuiche
Si tu interviens sur X qui dépend de Y et que tu découvres un bug dans Y, autant soumettre directement une résolution.
A condition d'en avoir l'autorité, dans ce cas des dépôts multiples qui plus est avec des "external" rendent le même service.
Envoyé par
DonQuiche
La nature humaine étant ce qu'elle est les individus partagent, contribuent et consomment davantage s'ils n'ont aucune configuration ou recherche à faire parce que tout est dans le même repo et qu'ils peuvent tout faire sans bouger de leur IDE. Dans le cas de Google c'est simple comme parcourir ton repo : contribuer à un autre projet est aussi simple que de contribuer à ton projet.
Sauf qu'il est peut probable que tu es "1 milliard de fichiers pour un poids total de 86 Téraoctets" sur ton disque ...
 1
1 |
 0
0 |


 Pourquoi Google a-t-il opté pour l'emploi d'un seul code base comme modèle de gestion de sources ?
Pourquoi Google a-t-il opté pour l'emploi d'un seul code base comme modèle de gestion de sources ? 





 Qu'en pensez-vous ?
Qu'en pensez-vous ?
