En mettant de côté les virgules qui ne sont pas à leur place, je trouve l'article un peu trop enthousiaste:
- Des milliers d'applications malveillantes
identifiées sur Play Store
- Ce résultat
est le signe que les processus employés par ces plateformes pour identifier les menaces, sont obsolètes.
- Des tests [...] ont également
prouvé que les performances de scan de « MassVet » sont bien plus élevées que celles des antivirus connus sur le marché.
- Le mécanisme utilisé par « MassVet » est
bien expliqué par ces chercheurs
Mouais... dans les faits, la technique est effectivement une technique statistique, et non basée sur des règles d'inférences, elle a donc l'avantage d'être scalable, mais elle a aussi ses limitations : si l'ensemble de référence est mal conçu (trop petit ou trop pauvre), la technique n'est plus aussi efficace. Autrement dit, cette technique peut marcher uniquement :
- parce que les stores utilisés sont déjà bien cleans, autrement des malwares passeraient comme des applications légitimes,
- parce que les stores sont bien remplis, autrement difficile d'avoir des données significatives étant donné l'hétérogénéité des apps
Ce n'est clairement pas le principe d'un anti-virus, qui cherche à savoir si l'app
contient un bout de code malveillant, et non si c'est un marginal. Parce que oui, cette technique ne cherche pas ce qu'il y a de malveillant dans l'app, elle se contente de trouver ceux qui sortent du lot. Et c'est pourquoi d'un côté ils peuvent se permettre de dire qu'ils trouvent des malwares "sans posséder au préalable dinformations sur elle", tout en n'oubliant pas que cette phrase est un raccourci maladroit: ce ne sont pas des infos absolues qu'ils utilisent (cette app a telle propriété, indépendamment d'autres apps) mais des infos relatives (cette app est similaire à telle autre de telle manière). Donc s'il est vrai qu'ils ne partent pas d'informations préalables sur l'app en elle-même, ils comptent sur le store pour leur fournir les données dont ils ont besoin, ce qui nous ramène à la qualité de base du store.
La comparaison à un antivirus est encore plus mal choisie car un anti-virus est censé tourner sur la machine d'un particulier, qui n'a pas facilement accès aux données d'un store complet : tu imagines ton antivirus qui doit télécharger les To d'apps de chacun des stores pour construire une grosse BDD avant de pouvoir te dire si oui ou non telle app est vérolée ? Je plains ton smartphone (et les auteurs auraient beaucoup d'humour : "
Note that such datasets are very compact, only 100 GB for 1.2 million apps."
")
. Et si je dois avoir Internet pour que mon antivirus fonctionne (comme ça les traitements sont fait sur un serveur), ça pose des questions de sécurité (e.g. interception des requêtes et envoit de faux "OK l'app est safe"
et de consommation (l'antivirus scan en continue, donc utilise en continue la bande passsante).
De plus, dire qu'ils le font "sans posséder au préalable dinformations sur elle" est d'autant plus vicieux, car ça laisse entendre qu'on utilise une technique générique. Or, dans les faits, il y a beaucoup d'hypothèses de départ qui se ramènent à des spécificités du store Android:
- les apps des stores sont variées, donc pas d'application à un store spécialisé,
- le store est clean (on analyse seulement les nouveaux entrants en prenant le store actual pour référence)... ce qui est complètement arbitraire (aucune évaluation n'est faite pour s'en assurer),
- la plupart des malwares sont des repackaging (supporté par une autre étude), et du coup ils se focalisent dessus (ils ne traitent pas tous types de malwares, un antivirus traite tout type de virus), donc le jour où ce ne sera plus vrai ce sera un autre type de malware qu'il faudra identifier en priorité, et MassVet on n'en parlera plus,
- quand ils comparent les interfaces, ils prennent en compte des éléments spécifiques à Android (Views et leurs events), ce qui n'est pas généralisable (en Java on peut utiliser SWT, AWT, Swing, JavaFX, etc., et dans d'autres langages on peut avoir aussi de nombreuses libs)
- ils font des calculs approximatifs pour être rapides, mais ces calculs intègrent 2 paramètres qui sont tunés pour les stores en question, donc ce n'est pas seulement approximatif, c'est aussi non généralisable (il faut refaire le tuning pour d'autres stores, ce qui implique d'avoir les données pour le faire)
- ils retirent des pubs, des bouts de code et des views en faisant des listes blanches, de façon à diminuer les faux positifs, listes blanches elle-même basées majoritairement sur les stores en question
- bien d'autres critères liés aux signatures et habitudes de programmation sont considérés pour diminuer encore les faux positifs
À ce niveau, j'ai lu la moitié de l'étude, et on tombe sur une pointe d'humour des auteurs : "
Such a treatment helps suppress false alarms and still preserves the generality of our design, which aims at detecting unknown malicious activities."
Muarf !
Un peu de sérieux messieurs : which aims at detecting unknown
possibly malicious activities
in Android-specific apps relatively to the apps already present in some given stores. Ce qui est drôle est que ça continue encore comme ça pendant plusieurs paragraphes. Je passe vite sur l'évaluation : une partie de la solution est tunée en se basant sur VirusTotal, et l'évaluation aussi, donc niveau biais de l'évaluation on aura vu mieux. Qui plus est, l'évaluation a aussi une partie manuelle, où on fait des groupes, on voit que VirusTotal en classifient certains comme malicieux et les autres il ne sait pas, et on extrapole a "tout le groupe est malicieux" (du coup, facile de trouver des milliers d'apps malicieuses). J'ai pas tout lu en détail cette partie, donc je reste très superficiel, mais en bref on a affaire à une solution finement paramétrée pour le Play Store de Google aujourd'hui, donc c'est pas dur de faire mieux que des solutions génériques telles que des antivirus.
Je ne critique donc pas la technique, mais bien la manière dont elle est "vendue".
 1
1 |
 0
0 |


 Des milliers d'applications malveillantes identifiées sur Play Store
Des milliers d'applications malveillantes identifiées sur Play Store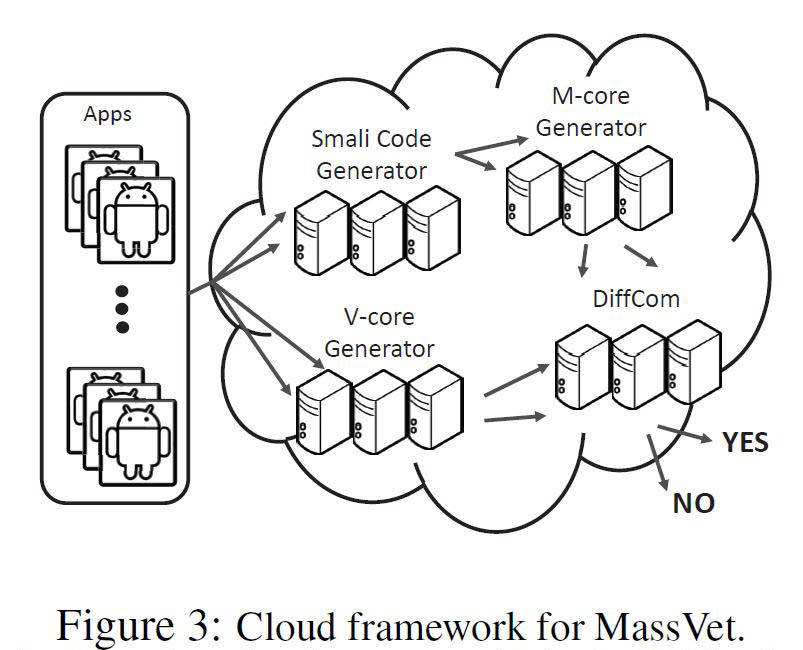
 Qu'en pensez-vous ?
Qu'en pensez-vous ?