

 Est-ce toujours plus rapide d'exécuter des opérations dans la mémoire des machines ?
Est-ce toujours plus rapide d'exécuter des opérations dans la mémoire des machines ?Non, selon une étude
L'une des préoccupations majeures pour un développeur est de pouvoir livrer des logiciels qui offrent des performances adéquates pour les différentes opérations à exécuter. Même pour un informaticien « occasionnel », il est évident que l'accès répété au disque peut dégrader considérablement la performance de son logiciel en termes de temps d'exécution des opérations.
Depuis plusieurs années - surtout avec l'avènement des domaines d'application informatique tels que le High Performance Computing, le Big Data, et le BI - les développeurs ont été en quête de nouvelles possibilités d'accroître la vitesse de traitement de leurs applications. L'informatique in-memory ou en mémoire a donc contribué à la réalisation de cet objectif.
L'informatique in-memory désigne en fait le stockage de l'information dans la mémoire RAM des machines plutôt que d'opter pour des accès fréquents au disque, qui ont tendance à ralentir considérablement l'exécution des opérations.
Les opérations en mémoire comprennent notamment la mise en cache d'innombrables quantités de données en permanence. Cela garantit des temps de réponse extrêmement courts pour les recherches. Pour les sites web encore, elles offrent la possibilité de stocker les données de session pour une performance optimale du site.
La tradition recommande donc aux développeurs de minimiser l'accès au disque en effectuant autant que possible le travail en mémoire, pour bénéficier de temps d'exécution plus courts. Mais, est-ce toujours plus rapide d'exécuter des opérations dans la mémoire des machines ? Non, selon une étude réalisée par des chercheurs des universités de Calgary et de British Columbia.
Pour le démontrer, les chercheurs ont effectué des expériences en supposant dès le départ que les traitements en mémoire préalables avant écriture sur le disque garantissent des temps d'exécution plus courts que les écritures répétées sur le disque.
L'idée est d'écrire un programme qui génère des données et de les enregistrer dans un fichier. Leur exemple consistait à créer une chaîne de caractères de 1Mo et de l'écrire sur le disque. Ils procèdent donc de deux manières différentes. La première consiste à effectuer au préalable les calculs en mémoire avant d'inscrire le résultat en une seule écriture sur le disque. La chaîne de 1Mo sera obtenue en concaténant des chaînes de tailles fixes. Par exemple, on peut obtenir la chaîne de 1Mo en concaténant 1.000.000 chaînes de 1 octet, ou en concaténant 100.000 chaînes de 10 octets, ou encore en concaténant 1.000 chaînes de 1000 octets. Les concaténations sont faites en mémoire et le résultat est inscrit sur le disque.
La deuxième méthode consiste à écrire les chaînes directement sur le disque, ce qui implique des accès répétés sans calculs en mémoire au préalable. Les données sont donc générées en petits morceaux et enregistrées immédiatement sur le disque.
Les programmes sont écrits en Java et Python et testés sous Windows et Linux. Dans chaque cas, ils ont mesuré le temps qu'il faut pour terminer l'opération pour pouvoir faire des comparaisons entre les deux méthodes.
Dans le cas in-memory, le temps d'exécution est la somme du temps mis pour effectuer les calculs en mémoire et du temps mis pour enregistrer le résultat sur le disque. Dans l'approche d'écritures répétées sur le disque, il n'y a pas d'opération en mémoire, donc on mesure uniquement le temps nécessaire pour effectuer les écritures sur disque.
Les résultats montrent que pour le programme en Java, sous Windows comme sous Linux, les accès répétés au disque donnent de meilleurs temps d'exécution pour les différentes tailles de chaînes fixées. Les résultats sont donnés dans les tableaux ci-dessous:
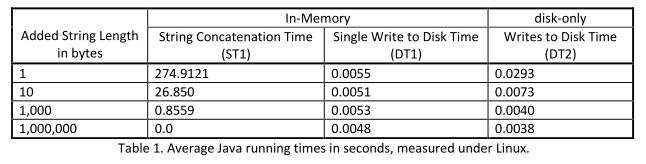
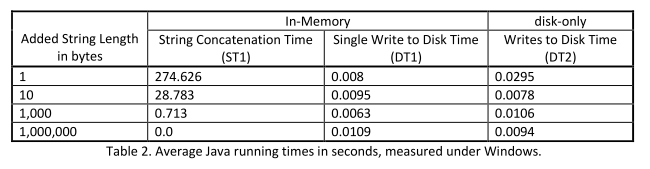
Pour le programme en Python, les expériences sous Linux montrent que lorsque le nombre de concaténations augmente, les opérations en mémoire semblent donner de meilleurs temps d'exécution. Mais sous Windows, les accès répétés au disque sont plus efficaces que les opérations en mémoire. Les résultats sont donnés dans les tableaux ci-dessous:
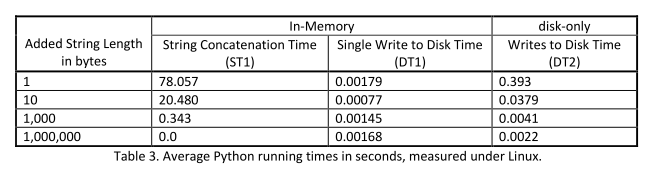
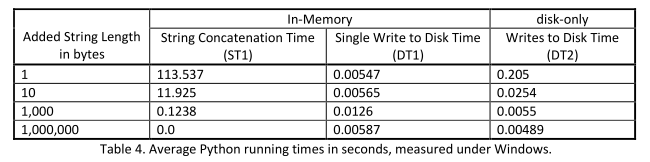
« Bien que dans de nombreux cas, les opérations en mémoire sont plus rapides qu'un algorithme équivalent qui accède au disque, les contre-exemples présentés, basés sur la vie réelle montrent que ce n'est pas toujours le cas ,» ont écrit les chercheurs.
Ces derniers notent aussi que de petits changements de code peuvent avoir des effets dramatiques sur les temps d'exécution. Ils sont en effet parvenus à exécuter la version in-memory du code Python plus vite sous Linux en changeant l'ordre de concaténation des chaines. Ce changement de code sous Windows n'a cependant pas amélioré le temps d'exécution. Ils concluent alors que ce qu'il faut pour améliorer la vitesse de travail en mémoire, c'est de savoir comment le système d'exploitation et le langage gèrent les opérations. Ils suggèrent donc qu'une connaissance du système et de meilleures pratiques de programmation sont nécessaires pour assurer que les opérations en mémoire puissent atteindre leur plein potentiel.
Source : When In-Memory Computing is Slower than Heavy Disk Usage (pdf)
Et vous ?
 Que pensez-vous des résultats de cette recherche ? S'accordent-ils avec la réalité ?
Que pensez-vous des résultats de cette recherche ? S'accordent-ils avec la réalité ?Mise à jour
Après avoir analysé l'étude, certaines personnes ont reporté qu'il y aurait des erreurs dans le code Java. Ce qui pourrait fondamentalement biaiser les résultats, du moins, pour le langage Java.
Vous avez lu gratuitement 6 148 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.




