Bonsoir,

Envoyé par
Michka1111
Envoyé par
fsmrel
Merci de vous être intéressé à larticle.
Pas de quoi, plaisant à lire, tant sur la forme que sur le fond.
Merci encore.
Envoyé par
Michka1111
Envoyé par
fsmrel
Dans son exemple, Ullman limite lunivers du discours à lagenda de lannée en cours : il ne cherche pas à modéliser un historique.
mais la relation universelle est bel et bien adaptée pour supporter les requêtes étoiles (clauses where restrictives sur des colonnes), et peu adaptée aux modifications performantes, en raison des données inutiles à la transaction impliquées dans la modification (un enregistrement pour modifier une colonne).
Ullman précise bien quil sagit de faciliter, simplifier les requêtes de lecture (le terme vue universelle serait plus approprié que celui de relation universelle), et que les mises à jour se font sous le capot (là où sont les tables de base). Si la relation universelle est comme une étoile, elle est quand même singulièrement dépourvue de branches...
Envoyé par
Michka1111
Envoyé par
fsmrel
Les données peuvent avoir à être modifiées, cas par exemple de la table CHR, quand il y aurait bilocation des professeurs (ou des étudiants), si un trigger tel que CHR_MAJ_TRIGGER ne linterdisait pas (situation à lépoque). Il est évident que si lon étendait les règles de gestion, par exemple quun professeur puisse être remplacé en cours dannée, on commencerait à rentrer dans le problème (pas trivial !) de la prise en compte de lhistorique, et là on pourrait aller très loin et séclater (cf. la normalisation en 6NF).
Il faut voir si les règles de gestion sont utiles et effectives dans le fonctionnel modélisé, dans l'exemple, il y a déja des restrictions pleines de bon sens mais triviales partant du principe qu'une personne est dépourvue d'ubicité.
A vue humaine les règles sont peut-être triviales, mais certainement pas du point de vue du SGBD : on doit lui mettre les points sur les i, doù la nécessité de commencer par la rédaction des règles de gestion aussi naïves peuvent-elles paraître, quon transpose ensuite dans le MCD sous forme de contraintes (identité, unicité, inclusion, exclusion, totalité, CIF, etc.). Ces règles sont là aussi pour quon puisse mettre en évidence les dépendances fonctionnelles (sans oublier les dépendances multivaluées, de jointure) nécessaires pour sassurer de la normalisation. Ceci fait, on demandera à lAGL (par exemple Looping) de traduire ces contraintes sous forme de contraintes SQL. Si le SGBD ne propose pas linstruction CREATE ASSERTION, on se rattrapera avec des triggers (voyez les triggers CHR_MAJ_TRIGGER, CHS_MAJ_TRIGGER), quand bien même sont-ils laborieux. A défaut, la base de données sera inévitablement truffée derreurs dont bien sûr lubiquité : quelles tombent sous le sens, la rédaction des règles de gestion nen reste pas moins essentielle, et comme dit mon voisin,
Scripta manent, verba volant.
Envoyé par
Michka1111
Envoyé par
fsmrel
On nest pas ici dans un « système historique ». Je rappelle que lunivers du discours décrit par Ullman nest pas concerné par le temps.
Pourtant, sa Relation Universelle est bien issue de la modélisation en étoile
Cette relation universelle nest jamais quune vue (au sens relationnel et SQL), cf. § 4.2 de larticle.
Dans son ouvrage auquel je fais référence, Ullman ne fait aucunement référence aux mots « star », « fact », « dimension » et autres termes connotés data warehouse : je ne vois pas en quoi sa relation universelle serait issue de la modélisation en étoile.
Envoyé par
Michka1111
Un cours est prodigué par un professeur aux élèves inscrits à ce cours
Certes, mais ça nest pas lobjet de la table CHR que jévoquais. Son prédicat est le suivant : Le cours C sera donné à lheure H dans la salle R.
Envoyé par
Michka1111
Les séries temporelles sont différentes des schémas étoiles historiques des systèmes transactionnels, bien que basées elles aussi sur des historiques.
En relationnel, on modélise lhistorisation des données, sous le contrôle de la 6NF, point barre.
Je vous renvoie à louvrage de référence
Temporal Data and The Relational Model. Remember
Pluralitas non est ponenda sine necessitate.
Envoyé par
Michka1111
Mon ouvrage de référence est Ralf Kimball "The Data Warehouse Toolkit"
Jai retrouvé dans mes archives le PDF de la version 2 de louvrage.
Je cite (page 9) :
Envoyé par
Ralf Kimball
The normalized structures must be off -limits to user queries because they defeat the twin goals of understandability and performance.
Plutôt que jumeaux, autant parler de triplés. Kimball oublie le troisième élément de la bande, lintégrité des données. A quoi bon seulement les « twin goals » si on mouline des données pourries, conséquences par exemple de la dénormalisation ? Quoi quil en soit, en plus de quarante ans de modélisation (MCD, MLD, MPD), jai toujours préconisé (quand SQL est arrivé), lencapsulation des requêtes complexes dans des vues (qui ne sont après tout que des tables virtuelles), en sorte que celles-ci soient
understandable pour les développeurs et autres utilisateurs.
Quant à la performance, sujet dont jai eu le souci depuis près de soixante ans (ben oui), Kimball me fait leffet de prêcher sur le mode incantatoire. De mon côté, je suis toujours resté dans les clous de la théorie relationnelle de Codd du jour où jai découvert celle-ci. Cela ma permis de mengager auprès de mes clients sur la performance des applications suite bien entendu à
prototypage à mort. En matière de performance je ne crois quaux mesures quon en a faites (voyez par exemple
ici). Quand les chiffres ne sont pas bons, on optimise, mais sans remettre en cause la modélisation si elle est correcte. Quand elle a été faite en dépit du bon sens, en toute incompétence, je la fais mettre à la poubelle et je prends ma casquette de concepteur pour piloter ceux qui referont les MCD.
Où sont les chiffres justifiant les allégations de Kimball ? En leur absence, je ne peux quêtre dun total scepticisme.
Je cite encore :
Page 21 :
Envoyé par
Ralf Kimball
Dimension tables typically are highly denormalized.
Et page 56
Envoyé par
Ralf Kimball
Efforts to normalize most dimension tables in order to save disk space are a waste of time.
Là encore, cest le mode incantatoire qui est de mise. Depuis tout ce temps où chez mes nombreux clients (tous des grands comptes, banque, assurance, industrie, distribution, transport ferroviaire, mutuelles, etc.), jai modélisé, audité, soigné les bases de données mal en point, je nai jamais eu à violer la normalisation (3NF), ou plutôt jai fait normaliser les tables qui ne létaient pas, justement pour des raisons dintégrité des données, voire de performance.
Au fait, Kimball parle de la troisième forme normale (3NF), mais sans en donner la définition. Etrange ! (On trouvera cette définition dans mon article, mais peut-être que Kimball et moi ne parlons pas de la même chose...). Non seulement la 3NF est mise à mal, mais cest très vraisemblablement le cas de la
2NF (pour Kimball, une table dénormalisée est forcément en 2NF ! cest magique !) Cest certainement aussi le cas de la 1NF sur laquelle Kimball jette manifestement un voile pudique, en omettant tout simplement den parler, alors quil sagit dun point capital. Pour Codd (inventeur de la théorie relationnelle), une relation est dénormalisée si elle viole la 1NF (
Further normalization of the data base relational model)...
Je rappelle la définition de la 1NF (cf.
Database Design and Relational Theory Normal Forms and All That Jazz) :
Let relation r have attributes A1, ..., An, of types T1, ..., Tn, respectively. Then r is in first normal form (1NF) if and only if, for all tuples t appearing in r, the value of attribute Ai in t is of type Ti (i = 1, ..., n).
Je rappelle aussi quune une relation est une valeur de variable relationnelle (
relvar).
Page 111 :
Envoyé par
Ralf Kimball
It is too limiting to think of products as belonging to a single hierarchy. Products typically roll up according to multiple defined hierarchies. All the hierarchical data should be presented in a single flattened, denormalized product dimension table.
On sen sort très bien même avec SQL, voyez
ici. Si les requêtes paraissent complexes, alors, comme dhabitude, encapsulons-les dans des vues.
Je suis désolé, mais je pourrais poursuivre
ad nauseam la litanie de mes observations en tant que concepteur et DBA...
 2
2 |
 0
0 |


 Bonjour,
Bonjour, , merci François !
, merci François !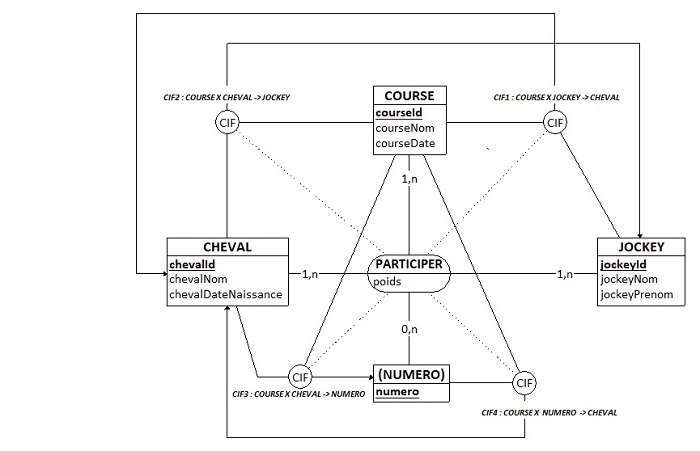
 !
!
.png)
 CHR (encapsulée dan la vue THR_V).
CHR (encapsulée dan la vue THR_V).