Envoyé par
Guesset

Bonjour,
Merci Jérôme.
J'ai vu ta bibliothèque vectorielle. C'est du travail. Je pense que la charge de tests doit avoir au moins égalé l'écriture même.
Si tu trouves des erreurs ou omissions dans le texte sur les SIMD entiers, n'hésite pas à les signaler. Cela me sera utile et en retour utile à tous.
Philippe
Bonjour, Philippe, merci, oui ce fût fastidieux au début. Et les tests unitaires ont été primordiales pour tester les résultats.
Mais j'ai eu l'aide de Peter, un ancien ingénieur en informatiques qui est bien plus doué que moi en maths

Malheureusement je n'ai plus de nouvelle depuis un moment (il profite de sa retraite pour voyager
")
)
Cette bibliothèque est loin d'être finalisée surtout justement en ce qui concerne la manipulation des valeurs de type byte, et Integer surtout. Il reste encore pas mal de méthode qui ne sont pas en assembleur

Je n'ai pas trouvé d'erreurs dans ton articles et comme je te l'ai dis je suis plus à l'aise avec les virgules-flottantes dans ce domaine. Par un contre un point important qu'il faudrait étoffer c'est l'alignement des données (surtout en 64bits) car l'utilisation d'un
movaps au lieu d'un
movups si les données ne sont pas alignées renverra obligatoirement des résultats erronés. (cf plus bas)
Ensuite il faut noter que les conventions d'appel ne sont pas les même suivant l'OS (Windows vs Unix)
Avec la version 3.1.x et sup de FPC on a accès à un nouveau mot-clef (sous Windows uniquement pour respecter la convention d'appel de celui-ci)
VectorCall. Ce qui permet de placer directement les paramètres d'une méthode dans les registres SIMD, ce qui évite donc l'appel a des
movXXX pour initialiser les registres.
Ex :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
{$MODESWITCH ADVANCEDRECORDS}
Type
TBZVector4fType = packed array[0..3] of Single; //< Tableau aligné pour les vecteur 4D Single
TBZVector4f = record
public
class operator +(constref A, B: TBZVector4f): TBZVector4f; {$ifdef USE_VECTORCALL} vectorcall; {$endif}overload;
case Byte of
0: (V: TBZVector4fType); //< Array access
1: (X, Y, Z, W: Single); //< Legacy access²
2: (Red, Green, Blue, Alpha: Single); //< As Color components in RGBA order
3: (AsVector3f : TBZVector3f); //< As TBZVector3f
4: (ST, UV : TBZVector2f); //< As Texture Coordinates
5: (Left, Top, Right, Bottom: Single); //< As Legacy Rect
6: (TopLeft,BottomRight : TBZVector2f); //< As Bounding Rect
end;
Implementation
class operator TBZVector4f.+(constref A, B: TBZVector4f): TBZVector4f; assembler; nostackframe; register; {$ifdef USE_VECTORCALL} vectorcall; {$endif}
asm
{$ifdef USE_VECTORCALL}
Addps xmm0, xmm1
{$else}
movaps xmm0, XMMWORD PTR [A]
addps xmm0, XMMWORD PTR [B]
{$endif}
movaps [RESULT], xmm0 // Ici il faut que je vérifie mais il me semble que du coup ce n'est plus obligatoire aussi avec VECTORCALL. Le registre XMM0 est automatiquement retourné
end; |
Comme je le notifie plus haut, pour l'alignement des données (en 64 bits uniquement. En 32 bits les données sont par défaut non-alignées quoi qu'il arrive) pour utiliser les instructions SIMD, avec FPC il est recommandé de rajouter les directives suivantes en début d'unité :
1
2
3
4
5
6
|
// Même pour un code compiler en 32bits ça ne mange pas de pain de rajouter ces quelques directives
{$ALIGN 16}
{$CODEALIGN CONSTMIN=16}
{$CODEALIGN LOCALMIN=16}
{$CODEALIGN VARMIN=16} |
puis en fonction de ou on se trouve dans le code il faut faire ainsi (surtout si on se trouve dans une autre unité que celle qui contient nos méthodes):
1
2
3
4
5
6
7
8
| Const
{$IFDEF CPU64}
{$CODEALIGN CONSTMIN=16}
cOneMinusVector4f : TBZVector4f = (x:-1;y:-1;z:-1;w:-1);
{$CODEALIGN CONSTMIN=4}
{$ELSE}
cOneMinusVector4f : TBZVector4f = (x:-1;y:-1;z:-1;w:-1);
{$ENDIF} |
1
2
3
4
5
6
7
8
| Var
{$IFDEF CPU64}
{$CODEALIGN VARMIN=16}
V1 : TBZVector4f;
{$CODEALIGN VARMIN=4}
{$ELSE}
V1 : TBZVector4f;
{$ENDIF} |
1
2
3
4
5
6
7
8
9
10
11
| Type
AClass = Class
protected
{$IFDEF CPU64}
{$CODEALIGN RECORDMIN=16}
FVector : TBZVector4f;
{$CODEALIGN RECORDMIN=4}
{$ELSE}
FVector : TBZVector4f;
{$ENDIF}
end; |
Voilà, sinon pour infos, j'ai effectué quelques changements dans ma bibliothèques mais non présents dans le dépôt que tu cite. Je me répète encore mais, dès que j'aurais un peu plus de temps pour harmoniser mon autre projet tout ce "beanz" sera en ligne
Merci
A bientôt
Jérôme
 0
0 |
 0
0 |


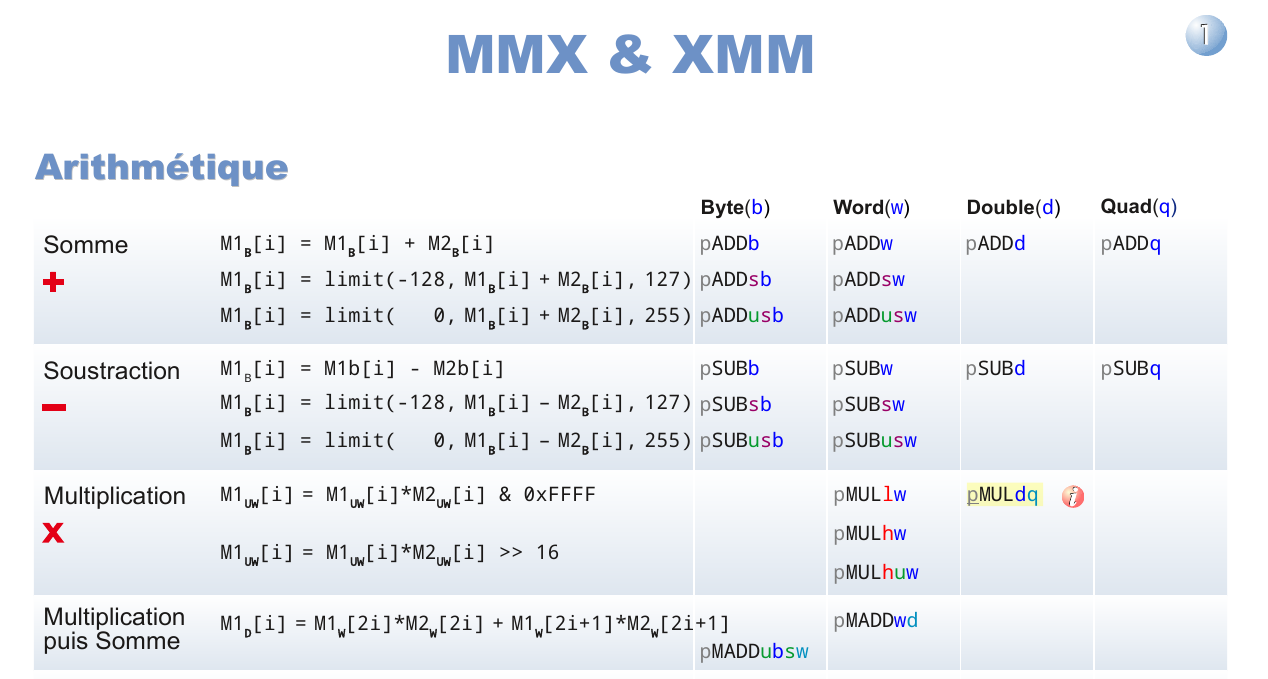
 Les "Single Instructions Multiple Data" sur des entiers
Les "Single Instructions Multiple Data" sur des entiers Lire l'article de présentation
Lire l'article de présentation