

 Google présente officiellement son API Data Loss Prevention,
Google présente officiellement son API Data Loss Prevention,qui aide les entreprises à protéger et réguler les données sensibles
Google vient de publier une nouvelle API qui aide les entreprises à protéger et réguler les données sensibles. L'API DLP (Data Loss Prevention), qui est en version bêta depuis mars, a été mise en disposition générale accompagnée de quelques nouvelles fonctionnalités.
Google explique que l'API DLP vous permet de comprendre et de gérer les données sensibles. Il fournit une classification rapide et évolutive et une rédaction facultative pour les éléments de données sensibles comme les numéros de carte de crédit, les noms, les numéros de sécurité sociale, les numéros de passeport, les numéros de permis de conduire internationaux sélectionnés et les numéros de téléphone. L'API classe ces données en utilisant plus de 50 détecteurs prédéfinis pour identifier les modèles, les formats et les sommes de contrôle, et même comprendre les indices contextuels. L'API prend en charge le texte et les images : il suffit d'envoyer des données à l'API ou de spécifier les données stockées sur vos instances Google Cloud Storage, BigQuery et Cloud Datastore.
« Ces nouvelles capacités de désidentification des données vous aident à travailler avec des informations sensibles, tout en réduisant le risque que des données sensibles soient révélées par inadvertance. Si, comme beaucoup d'entreprises, vous suivez le principe du moindre privilège ou accès aux données (n'utilisez ou n'exposez que les données minimales requises pour un processus métier approuvé), l'API DLP peut vous aider à appliquer ces principes dans les applications de production et les workflows de données . Et parce que c'est une API, le service peut être pointé vers n'importe quelle source de données ou système de stockage », assure Scott Ellis, Product Manager chez Google.
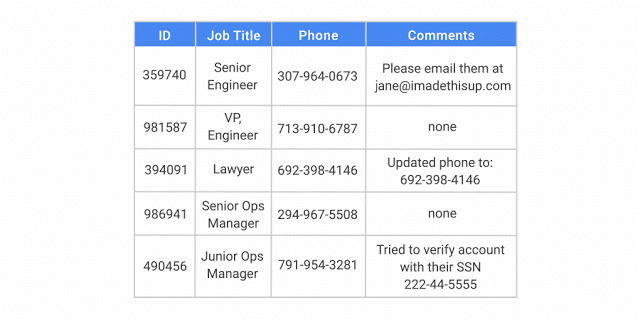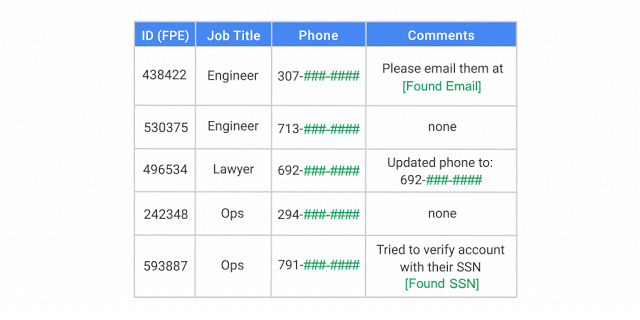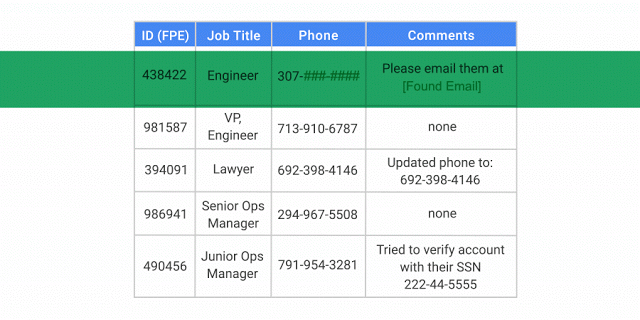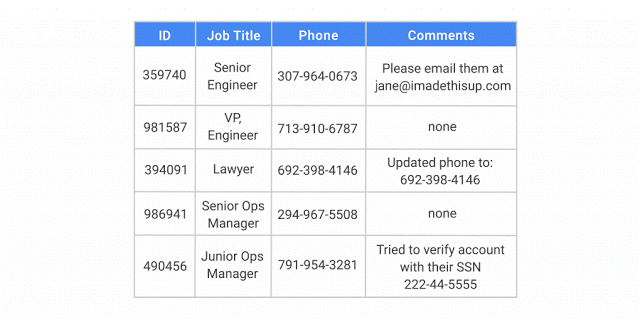
Avec l'API DLP, vous pouvez classer et masquer les éléments sensibles à la fois dans les données structurées et dans les données non structurées.
L'API DLP prend désormais en charge une variété de nouvelles options de transformation de données.
Rédaction et suppression
La rédaction et la suppression permettent de supprimer des valeurs entières ou des enregistrements entiers d'un ensemble de données. Par exemple, si un agent de support travaillant dans une interface utilisateur de support client n'a pas besoin de voir les détails d'identification pour résoudre le problème, vous pouvez décider de supprimer ces valeurs. Ou, si vous analysez les grandes tendances démographiques, vous pouvez décider de supprimer les enregistrements contenant des données démographiques uniques ou des attributs rares, car ces caractéristiques distinctives peuvent présenter un risque plus élevé.
.

L'API DLP identifie et modifie un nom, un numéro de sécurité sociale, un numéro de téléphone et une adresse e-mail
Le masquage partiel
Le masquage partiel obscurcit une partie d'un attribut sensible - par exemple, les sept derniers chiffres d'un numéro de téléphone américain. Dans cet exemple, un numéro de téléphone à dix chiffres ne conserve que l'indicatif régional.
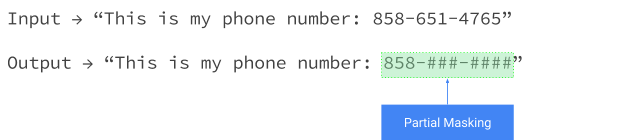
Tokenization ou hachage sécurisé
La tokenisation, également appelée hachage sécurisé, est une transformation algorithmique qui remplace un identifiant direct par un pseudonyme ou un jeton. Cela peut être très utile dans les cas où vous devez conserver un identifiant d'enregistrement ou joindre des données, mais ne souhaitez pas révéler les éléments sous-jacents sensibles. Les jetons sont basés sur des clés et peuvent être configurés pour être réversibles (en utilisant la même clé) ou non réversibles (en ne conservant pas la clé).
L'API DLP prend en charge les types de jetons suivants:
- Format-Preserving Encryption - un jeton de la même longueur et du même jeu de caractères.
- Des hachages sécurisés basés sur des clés - un jeton qui est une chaîne hexadécimale de 32 octets générée à l'aide d'une clé de chiffrement de données.
Masquage dynamique des données
L'API DLP peut appliquer diverses techniques de désidentification et de masquage en temps réel, ce que l'on appelle parfois le "Dynamic Data Masking" (DDM). Cela peut être utile si vous ne voulez pas modifier vos données sous-jacentes, mais que vous souhaitez les masquer lorsqu'elles sont vues par certains collaborateurs ou utilisateurs. Par exemple, vous pouvez masquer des données lorsqu'elles sont présentées dans une interface utilisateur, mais nécessitent des privilèges spéciaux ou génèrent des journaux d'audit supplémentaires si quelqu'un doit consulter les informations personnelles identifiables sous-jacentes (PII). De cette façon, les utilisateurs ne sont pas exposés aux données d'identification par défaut, mais seulement lorsque les besoins de l'entreprise le dictent.
Source : Google
Vous avez lu gratuitement 458 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.