

 Deep learning : NVIDIA sattaque aux résultats de benchmarks dIntel
Deep learning : NVIDIA sattaque aux résultats de benchmarks dIntelqui présentaient les CPU Xeon Phi plus performants que les GPU Maxwell
GPU vs CPU : quel est le type de processeur le plus performant pour le deep learning ? Intel et NVIDIA saffrontent sur la question et se rangent logiquement du côté le plus favorable à leurs produits.
En juin dernier, lors de la conférence internationale sur le calcul haute performance (ISC 2016), Intel a présenté une slide sur ses dernières puces Xeon Phi Knights Landing. Alors que le fabricant de puces voulait mettre en avant les performances de ses processeurs, Intel a essayé de réfuter ce qui est considéré comme une vérité dans le domaine du calcul haute performance : si les processeurs (CPU) sont faits pour les calculs à haute précision, quand on vient au deep learning, les processeurs graphiques (GPU) sont une meilleure solution, parce que les réseaux neuronaux ne requièrent pas de calculs à haute précision. En plus de cela, le fabricant de CPU a décidé de sattaquer directement au fabricant de processeurs graphiques NVIDIA.
Daprès les résultats de Benchmarks dIntel, ses CPU sont plus performants que les GPU dans le cadre du deep learning. Entre autres revendications, Intel a en effet présenté ses puces Xeon Phi comme étant jusquà 2,3 fois plus rapides que les GPU Maxwell de NIVIDIA pour la formation de réseaux neuronaux.
Le deep learning et le machine learning en général constituent un énorme marché avec un potentiel qui est encore très peu exploité. De quoi donc attirer la convoitise de tous les constructeurs susceptibles den tirer profit. Jusque dernièrement, Intel était en mauvaise posture sur ce marché, où il est devancé par les GPU modernes de NVIDIA. Mais le fabricant de CPU tente de rattraper son retard notamment avec le récent rachat de Nervana, une start-up spécialisée dans le deep learning. La semaine dernière, en réponse aux GPU de NVIDIA, Intel a également annoncé à la conférence Intel Developer Forum (IDF) 2016, son nouveau processeur Xeon Phi Knights Mill, optimisé pour le deep learning.
Deux mois après ces revendications, NVIDIA réagit dans un billet de blog pour « corriger les erreurs des benchmarks de deep learning dIntel », daprès le titre de son billet. NVIDIA prend soin de souhaiter à Intel la bienvenue dans le monde du deep learning, mais estime que ses déclarations ne sont pas valides parce quelles reposent sur des données qui sont obsolètes. « C'est formidable quIntel travaille actuellement sur le deep learning. C'est la révolution informatique la plus importante à l'ère de l'intelligence artificielle et le deep learning est trop important pour être ignoré. » Affirme NVIDIA, avant dajouter : « Mais ils devraient se baser sur des faits justes ».
En ce qui concerne le fait que les CPU Xeon Phi Knights Landing seraient jusquà 2,3 fois plus rapides que les processeurs graphiques Maxwell, NVIDIA explique que cest seulement parce quIntel a utilisé une version obsolète de 18 mois d'un benchmark de deep learning. Avec la dernière implémentation du benchmark, NVIDIA montre que ses GPU Maxwell surpassent les CPU dIntel de 30 % en rapidité. Lorsque NVIDIA compare les puces Xeon Phi avec ses derniers processeurs graphiques Pascal, la différence est de 90 % à son avantage au lieu de 30 %. NVIDIA affirme encore que son système DGX-1 dédié au deep learning est jusquà 5,3 fois plus rapide que quatre serveurs Xeon Phi.
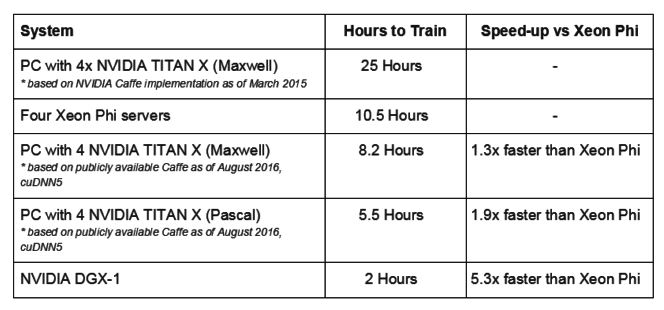
Résultats de tests de NVIDIA
Le fabricant de GPU sattaque tour à tour aux revendications dIntel en essayant de montrer les différentes failles. Intel a par exemple affirmé que 128 serveurs Xeon Phi offrent un gain de performance de 50 fois plus élevé quavec un seul serveur Xeon Phi, alors que la mise à léchelle nest pas possible avec les GPU. Ici encore, NVIDIA a totalement réfuté laffirmation du fabricant de CPU, en expliquant que Baidu a déjà publié des résultats montrant une augmentation de performance presque linéaire jusquà 128 GPU sur une architecture Maxwell, donc beaucoup mieux que la mise à léchelle avec les CPU Xeon Phi dIntel.
Contacté par Ars Technica pour savoir sil a une objection aux déclarations faites dans le billet de blog de NVIDIA, le fabricant de puces répond que « cest tout à fait compréhensible que NVIDIA soit préoccupé par Intel dans cet espace [le deep learning] ». Et dajouter : « Intel publie régulièrement des allégations de performance basées sur des solutions accessibles au public au moment [de ces déclarations], et nous soutenons nos données. »
Source : NVIDIA
Et vous ?
 Quen pensez-vous ?
Quen pensez-vous ?Voir aussi :
NVIDIA annonce son architecture Pascal et CUDA 8, les opérations d'apprentissage de réseaux neuronaux accélérées d'un facteur douze IA : Intel s'offre l'expertise de Nervana Systems dans le deep learning, pour améliorer les performances de ses processeurs Xeon et Phi Xeon
Vous avez lu gratuitement 1 189 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.


