

 Erreur 404 : Mozilla veut fouiller dans les archives du web pour ressortir les pages introuvables
Erreur 404 : Mozilla veut fouiller dans les archives du web pour ressortir les pages introuvablesla fonctionnalité No More 404s en expérimentation
Lorsque vous naviguez sur internet, il peut arriver quen lançant un lien, vous tombiez sur une page avec un message derreur 404 file not found (fichier introuvable). Cela se produit en général lorsque la page que vous recherchez nexiste pas ou a tout simplement changé dadresse, de nom ou a été supprimée.
On peut rencontrer ce problème après avoir effectué une recherche sur Google ou Bing par exemple. Le moteur de recherche puise dans sa mémoire pour vous sortir des résultats en fonction des pages quil a rencontrées sur le net et enregistrées. Pour une page quil a mémorisée, si elle a été effacée sans que le moteur ne sen rende compte et que son lien vous est proposé dans les résultats de recherche, en cliquant dessus, vous tomberez sur une page Not found. Que faire dans ce cas ?
Jusquà présent, aucune solution magique nexiste, et ce, quel que soit le navigateur. Google propose toutefois quelque chose pour Chrome avec les pages mises en cache, mais pendant combien de temps ces données mises en mémoire seront-elles conservées ?
Mozilla veut donc permettre aux utilisateurs de Firefox de retrouver des pages qui nexistent plus ou qui ont changé dadresse peut-être depuis des années. Pour cela, la fondation travaille en collaboration avec lInternet Archive (IA), un organisme à but non lucratif consacré à larchivage du Web. LIA dispose dun outil baptisé Wayback Machine. Lancé depuis 2001, la Wayback Machine est une archive numérique du World Wide Web et dautres informations sur le net. Le service permet aux utilisateurs de voir les versions archivées de pages Web à travers le temps. Lidée du partenariat avec Mozilla est donc de fouiller dans les archives du Web générées par la Wayback Machine pour ressortir aux utilisateurs de Firefox les pages introuvables si possible.
De manière pratique, quand un utilisateur de Firefox va tomber sur une page avec le message derreur 404 file not found, un lien en haut de page sera proposé à ce dernier pour retrouver une version de la page introuvable enregistrée dans la Wayback Machine. Larchive numérique de lInternet Archive contient à ce jour près de 500 milliards de pages web enregistrées au fil du temps.
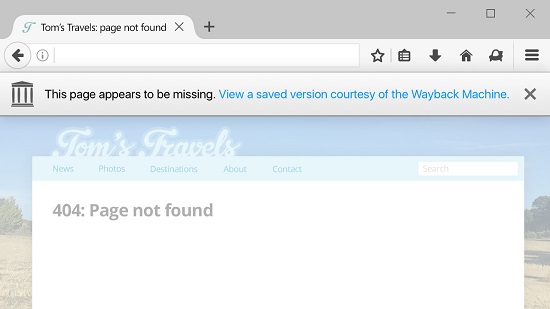
Cette fonctionnalité baptisée No More 404s est actuellement en test via le programme Firefox Test Pilot. Ce programme permet de tester de nouvelles fonctionnalités Firefox avant quelles débarquent chez le public. Outre la fonctionnalité No More 404s, Firefox Test Pilot permet également de tester bien dautres fonctionnalités qui pourraient être livrées avec le navigateur de Mozilla. Ces fonctionnalités sont disponibles en test via une extension que vous devrez installer.
La fonctionnalité No More 404s peut être intéressante, mais peut également susciter des questions de confidentialité. Il ne faut pas en effet oublier que les autorités européennes de protection de la vie privée ont dû dernièrement mener beaucoup de batailles pour contraindre Google à respecter le droit à loubli pour les Européens. Si le géant de la recherche en ligne a fait quelques concessions, lapplication du droit à loubli en Europe reste encore un peu restreinte, même si Google a promis que les URL déférencées ne seront plus visibles par les utilisateurs localisés dans le pays de la personne qui a fait la requête de suppression. No More 404s peut en effet faire ressortir des pages qui ont été supprimées alors que celles-ci remettaient en cause la protection de la vie privée de certains individus. La fondation Mozilla ayant développé des principes de respect de la vie privée, a-t-elle vraiment mesuré la portée de la fonctionnalité No More 404s ? Si la fonctionnalité doit être livrée, des mesures supplémentaires seront-elles prises pour limiter la fonctionnalité à un certain type dinformations recherchées ?
Quoi qu'il en soit, Mozilla ne crée rien de nouveau, puisque la fondation ne fera juste qu'informer les utilisateurs de Firefox qui ne le savaient pas, qu'un outil est disponible sur le Web pour leur permettre de retrouver des pages qui ne sont plus disponibles.
 Télécharger lextension Firefox Test Pilot pour tester la fonctionnalité No More 404s (sur Windows, Mac, Linux)
Télécharger lextension Firefox Test Pilot pour tester la fonctionnalité No More 404s (sur Windows, Mac, Linux)Et vous ?
Quen pensez-vous ?Voir aussi :
Firefox 48 débarque enfin avec le support du multiprocessus, cette nouvelle version rend aussi obligatoire la signature numérique des extensions Firefox 48 : Mozilla améliore la protection contre des téléchargements potentiellement dangereux et procède à une refonte de l'interface utilisateur Mozilla va bloquer le contenu Flash non essentiel dans son navigateur, en 2017 Firefox va exiger une approbation par clic des utilisateurs
Vous avez lu gratuitement 47 994 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

