

 scikit-learn est la bibliothèque de référence en apprentissage automatique en Python (à l'exception de l'apprentissage profond). La prochaine version, la 0.22, pointe le bout de son nez : la première RC est maintenant disponible pour les tests.
scikit-learn est la bibliothèque de référence en apprentissage automatique en Python (à l'exception de l'apprentissage profond). La prochaine version, la 0.22, pointe le bout de son nez : la première RC est maintenant disponible pour les tests. Au menu, on compte notamment l'imputation plus avancée qu'actuellement, avec la classe IterativeImputer, pour la gestion de valeurs manquantes. Cette fonction est toujours expérimentale et doit être activée manuellement. Maintenant, on compte aussi KNNImputer pour effectuer l'imputation à l'aide des k plus proches voisins.
Les nouveaux algorithmes de dopage à base d'arbres, apparus avec scikit-learn 0.21, gèrent de manière native les valeurs manquantes : il n'y a plus besoin d'imputation lors de l'entraînement ou la prédiction. (Ces estimateurs restent expérimentaux ) Dans l'implémentation, le regroupement des échantillons selon la valeur d'un attribut se fait à l'aide d'une classe réservée aux échantillons pour lesquels cet attribut manque.
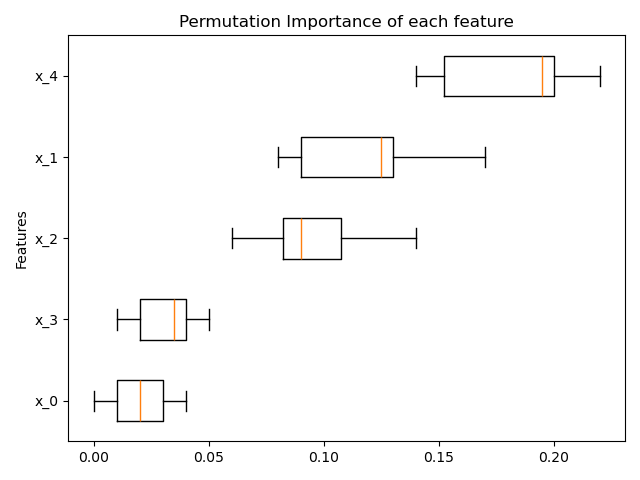
Pour l'inspection des modèles, scikit-learn fournit un calcul d'importance par permutations (une mesure similaire à l'importance définie pour des arbres de décision). Cette valeur a tendance à être plus précise dans les cas où les données comportent de nombreuses colonnes fortement corrélées.
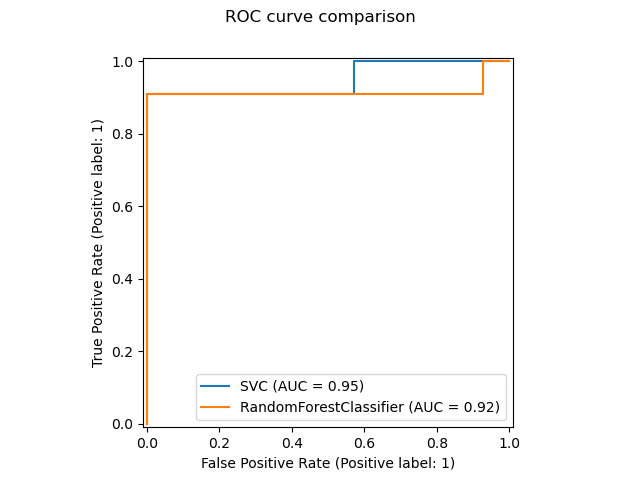
La fonction plot_roc_curve est une nouvelle manière d'afficher la courbe ROC pour un modèle donné, mais en utilisant des données de prédiction sur un jeu de test déjà disponibles. En particulier, cela signifie qu'il est très facile de créer un nouveau graphique, puisque les calculs les plus lourds peuvent être réutilisés. D'autres fonctions similaires pour les dépendances partielles, les courbes précision-rappel et la matrice de confusion existent.
L'empilement de modèles est une technique simple pour combiner plusieurs modèles et ainsi obtenir un nouveau modèle qui fait moins d'erreurs que le meilleur des modèles empilés (propriété souvent vraie en pratique). Les versions les plus évoluées de ce mécanisme utilisent un modèle d'apprentissage par-dessus les modèles empilés. Cette version améliorée est désormais disponible dans scikit-learn (en sus de la classification par vote).
Les modèles à base d'arbres peuvent être élagués, c'est-à-dire que certains tests sont retirés pour diminuer la complexité de l'arbre. Cette technique permet parfois d'améliorer la performance en généralisation de l'arbre. scikit-learn implémente une technique d'élagage après l'entraînement qui minimise la somme pondérée de l'erreur effectuée par l'arbre sur les données d'entraînement (minimale pour un arbre très complexe) et du nombre de feuilles de cet arbre.
La version 0.22 est la deuxième à ne plus être disponible que pour Python 3. Elle marque aussi une différence plus claire entre les API privées (noms qui commencent par _, comme d'habitude en Python) et publiques. Les fonctions publiques sont documentées et les changements d'interface qui peuvent casser le code existant sont limités au maximum (si c'est nécessaire, les développeurs préviennent deux versions mineures à l'avance : certains changements pour la 0.24 sont annoncés lors de la sortie de la 0.22). Certaines fonctions utilitaires étaient disponibles de manière publique, alors qu'ils n'étaient pas prévus pour cet usage ; de même, pour importer des sous-modules, plusieurs syntaxes étaient parfois possibles (from sklearn.cluster import Birch et from sklearn.cluster.birch import Birch , la deuxième écriture n'étant plus disponible dès la version 0.22)
Voir aussi : la liste complète des changements, les nouvelles fonctionnalités mises en évidence, le nouveau site Web.

