

 On en parle depuis des lustres, voici le temps des officialisations. Les cartes graphiques Intel Xe ont commencé comme des rumeurs, puis ont été annoncées en juin 2018. Depuis lors, les détails réels et officiels n'ont pas été nombreux. Certaines rumeurs, comme la présence de mémoire HBM sur toutes les cartes, se sont révélées fausses par la suite
On en parle depuis des lustres, voici le temps des officialisations. Les cartes graphiques Intel Xe ont commencé comme des rumeurs, puis ont été annoncées en juin 2018. Depuis lors, les détails réels et officiels n'ont pas été nombreux. Certaines rumeurs, comme la présence de mémoire HBM sur toutes les cartes, se sont révélées fausses par la suite
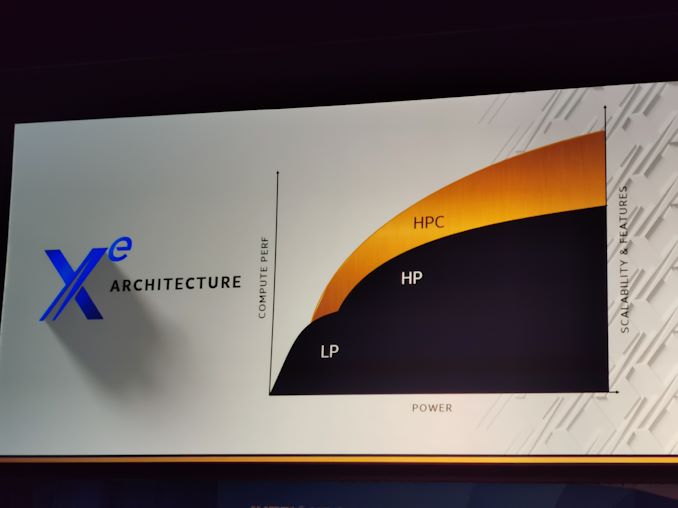
Intel prévoit trois gammes de cartes. Les Xe LP (low power) sont prévues comme cartes intégrées ou d'entrée de gamme, avec une consommation énergétique entre cinq et vingt watts (mais possiblement jusque cinquante). Les Xe HP (high performance) sont prévues comme les cartes principales pour les joueurs, les centres informatiques et les applications d'"intelligence artificielle", avec une puissance entre septante-cinq et deux cent cinquante watts. La troisième gamme, Xe HPC, vise les superordinateurs, avec une performance en calcul bien plus élevée : ces processeurs pourront monter à plusieurs milliers d'unités d'exécution (chacune pouvant effectuer des calculs en virgule flottante jusque quarante fois plus vite que les unités actuelles qui ne visent pas du tout le même marché).
Ces processeurs graphiques seront programmables selon trois modes : SIMD, comme les CPU actuels (une seule instruction opère sur une série de valeurs à la fois), avec des instructions comme SSE ou AVX ; SIMT, comme les GPU actuels (une seule instruction opère sur un grand nombre de valeurs à la fois dans des fils d'exécution séparés) ; SIMD et SIMT, pour une performance maximale. En pratique, ces processeurs graphiques peuvent fonctionner sur des vecteurs de taille très variable, ce qui mène à la distinction entre SIMD et SIMT.

L'architecture mémoire des processeurs graphiques est entièrement revue, pour être utilisable à toutes les échelles où les processeurs Xe seront disponibles. Elle porte le nom de XeMF (Xe memory fabric) et peut se connecter à une série de canaux de mémoire à haute bande passante (de type HBM).

Aussi, ces processeurs disposeront d'un énorme cache (en nombre de bits stockables et en millimètres carrés sur le processeur). Rambo sera unifié, c'est-à-dire accessible tant par le CPU que le GPU : il devrait aussi servir à la communication entre processeurs graphiques. Son objectif principal est de fournir une énorme bande passante pour servir autant que possible les unités de calcul en nombres (FP64, surtout). Il ne devrait pas être une limite pour les diverses applications des GPU.

Au niveau matériel, ce cache Rambo devrait correspondre à une puce intégrée dans le boîtier à l'aide de la technologie Foveros : plusieurs puces graphiques seront interposées dans le même boîtier et liées au même cache, pour faciliter les communications (au moins pour la déclinaison HPC).

Le premier GPU à destination des superordinateurs sera le Ponte Vecchio, fabriqué sur le processus en 7 nm d'Intel (qui suit le 10 nm, en cours de déploiement). Il contiendra seize pucettes de calcul sur une même puce, avec d'énormes quantités de HBM.

L'utilisation prévue de ce monstre de puissance, pour le superordinateur Aurora (États-Unis), sera dans des nuds comportant deux processeurs Intel Xeon de génération Sapphire Rapids (avec des curs Willow Cove), plus six processeurs graphiques Ponte Vecchio. Chaque processeur pourra communiquer directement avec les sept autres du même nud, ce qui garantit une faible latence et une haute bande passante.

Source : AnandTech (images), WccfTech.

