

 Facebook va proposer en open source LogDevice, son système de stockage de journaux
Facebook va proposer en open source LogDevice, son système de stockage de journauxbonne nouvelle pour les administrateurs de base de données ?
Dans le cadre de sa conférence Scale, Facebook a fait part de son intention de mettre en open source LogDevice, sa solution personnalisée pour stocker les journaux collectés à partir des centres de données distribués.
Les journaux sont utilisés pour suivre les événements de la base de données. Par exemple, si un serveur souffre d'une panne pour quelque raison que ce soit, les entreprises ont besoin d'un moyen de déboguer, d'effectuer des vérifications de sécurité et d'assurer la cohérence entre les serveurs. Ceci est particulièrement important pour Facebook, qui détient énormément de contenu dans ses centres de données massifs à travers le monde.
Dans un billet de blog, Mark Marchukov, un ingénieur de Facebook, a tenté dexpliquer limportance des journaux pour une entreprise :
« Un journal est le moyen le plus simple d'enregistrer une séquence ordonnée d'enregistrements immuables et de les stocker de manière fiable. Créez un service distribué à forte intensité de données et vous risquez d'avoir besoin d'un journal ou deux. Chez Facebook, nous développons beaucoup de grands services distribués qui stockent et traitent des données. Vous souhaitez connecter deux étapes d'un pipeline de traitement de données sans vous soucier du contrôle de flux ou de la perte de données ? Demandez à une étape d'écrire dans un journal et à lautre de le lire. Maintenir un index sur une grande base de données distribuée ? Demandez au service d'indexation de lire le journal de mise à jour pour appliquer tous les changements dans le bon ordre. Une séquence d'éléments de travail doit-elle être exécutée dans un ordre spécifique une semaine plus tard ? Écrivez-les dans un journal, faites décaler le consommateur dune semaine. Vous rêvez de transactions distribuées ? Un journal avec une capacité suffisante pour commander toutes vos écritures les rend possibles. Des problèmes de durabilité ? Utilisez un journal en écriture. »
Comme il la rappelé, le journal peut être visualisé sous la forme d'un fichier orienté vers l'enregistrement, l'ajout et la suppression. Il explique notamment que :
- « orienté enregistrement » signifie que les données sont écrites dans le journal dans des enregistrements indivisibles plutôt que des octets individuels. Plus important encore, un enregistrement est la plus petite unité d'adressage : un lecteur commence toujours à lire à partir d'un enregistrement particulier (ou à partir du prochain enregistrement à ajouter au journal) et reçoit les données d'un ou de plusieurs enregistrements à la fois. Plus important encore, la numérotation des enregistrements n'est pas garantie dêtre continue. Il peut y avoir des lacunes dans la séquence de numérotation, et en écriture il nest pas possible de savoir à l'avance quel numéro de séquence logarithmique (LSN) sera attribué à son enregistrement lors d'une écriture réussie. Étant donné que LogDevice n'est pas lié par l'exigence de numérotation en octets continus, il peut offrir une meilleure disponibilité d'écriture en présence de pannes ;
- les journaux sont naturellement ajoutés uniquement. Aucun support pour modifier les enregistrements existants n'est nécessaire ou fourni ;
- les journaux devraient exister pendant un temps relativement long (des jours, des mois ou même des années) avant d'être supprimés. Le principal mécanisme de récupération de l'espace pour les journaux est le trimming, qui revient à abandonner les enregistrements les plus anciens selon une politique de rétention basée sur le temps ou l'espace.
« Ce que nous avons trouvé commun à la plupart de nos applications d'enregistrement est l'exigence d'une forte disponibilité d'écriture. Les enregistreurs n'ont tout simplement pas dendroit où garder leurs données, même pendant quelques minutes. LogDevice doit donc être là pour eux. L'exigence de durabilité est également universelle. Comme dans n'importe quel système de fichiers, personne ne veut entendre que ses données ont été perdues après avoir reçu un accusé de réception confirmant une inscription réussie à un journal. Les erreurs matérielles ne sont pas une excuse. Enfin, nous avons découvert que, bien que la plupart du temps, les enregistrements de journaux soient lus à quelques reprises, et très peu de temps après qu'ils soient ajoutés à un journal, nos clients effectuent occasionnellement des backfills massifs. Un backfill est un modèle d'accès difficile où un client de LogDevice lance au moins un lecteur par journal pour les enregistrements qui sont vieux de plusieurs heures ou même plusieurs jours. Ces lecteurs procèdent ensuite à la lecture de tous les éléments dans chaque journal à partir de ce point. »
En clair, LogDevice est capable d'enregistrer des données indépendamment du matériel ou des problèmes de réseau. Sil survient un problème, il va tout simplement arrêter la tâche de collecte des journaux. Et lorsque tout revient dans lordre, LogDevice peut restaurer des enregistrements entre cinq et dix gigaoctets par seconde.
Voici comment le logiciel fonctionne :
« Tout d'abord, nous découpons la commande des enregistrements dans un journal à partir du stockage réel des copies d'enregistrements. Pour chaque connexion à un cluster LogDevice, LogDevice exécute un objet séquenceur dont le seul travail consiste à émettre des nombres séquentiels augmentant de façon monotonique, car les enregistrements sont ajoutés à ce journal. Le séquenceur peut fonctionner n'importe où, à linstar dun noeud de stockage ou dun noeud réservé pour le séquençage, et ajouter une exécution qui neffectue aucun stockage. »
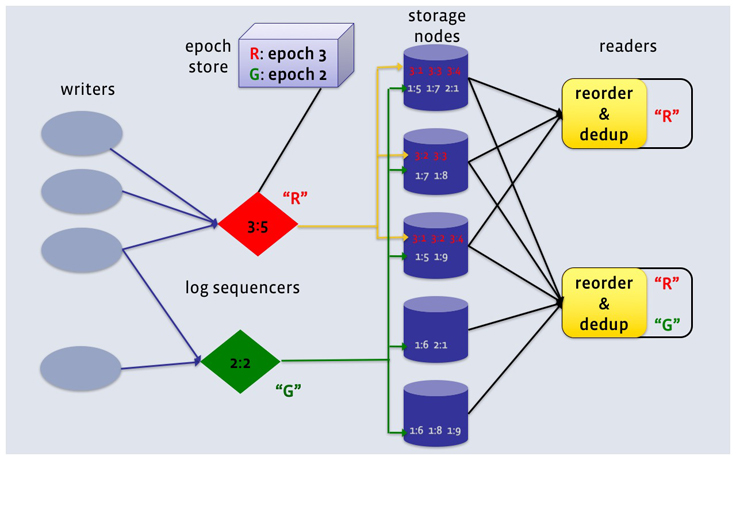
La séparation du séquençage et du stockage dans LogDevice
Une fois qu'un enregistrement est marqué avec un numéro de séquence, les copies de cet enregistrement peuvent potentiellement être stockées sur n'importe quel nud de stockage dans le cluster. Leur placement n'affectera pas la propriété de lecture répétable du journal tant que les lecteurs peuvent trouver et récupérer efficacement les copies.
Un client qui souhaite lire un journal en ligne particulier contacte tous les nuds de stockage autorisés à stocker les enregistrements de ce journal.
Source : Facebook
Et vous ?
 Qu'en pensez-vous ?
Qu'en pensez-vous ?
Vous avez lu gratuitement 13 557 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.