

 CppCon 2016 : Bjarne Stroustrup parle de l'évolution de C++ et s'intéresse à son passé,
CppCon 2016 : Bjarne Stroustrup parle de l'évolution de C++ et s'intéresse à son passé, à son présent mais aussi à son futur
Durant lédition 2016 de la conférence annuelle de la communauté C++ CppCon, le professeur de science informatique danois et créateur du langage Bjarne Stroustrup a tenu à présenter les évolutions du langage, notamment en évoquant son passé, son présent, mais également son futur.
« Je me demandais ce dont jallais parler durant cette conférence en tant quorateur. Puis jai regardé le programme et jai réalisé quil y avait une grosse liste de choses bien détaillées, que ce soit sur le langage, les bibliothèques, etc. Aussi, je me suis dit que je nallais pas me lancer dans cette voie. Jessaie au contraire de parler de quelque chose de plus général. Jessaie de parler dévolution. Jessaie de retourner en arrière pour comprendre la raison pour laquelle C++ a connu du succès », a-t-il déclaré en guise dintroduction devant lauditoire.
Les points sur lesquels Bjarne Stroustrup s'est appesanti sont notamment :
- le passé : pourquoi est-ce que C++ a connu le succès ?
- en répondant aux questions avant que les gens ne les posent,
- en ne suivant pas la masse ;
- le présent : comment la standardisation façonne-t-elle le C++ ?
Elle aspire à la stabilité via la compatibilité ; - le futur : que devons-nous faire ?
- concentrer nos efforts à servir la communauté C++ actuelle et à venir,
- ne pas se dissiper en essayant de plaire à tous ;
- le futur proche : comment s'y préparer ?
- trouver des moyens pour utiliser des fonctionnalités des spécifications techniques ISO,
- développer des lignes directrices.
Durant son intervention, il a donné son avis, par exemple, sur les fonctionnalités dun bon langage de programmation. Selon lui, bien que tout langage ait besoin de bonnes fonctionnalités fondamentales (par exemple, des mécanismes pour aider à concevoir son code, mais également une bibliothèque standard), un (bon) langage ne saurait se limiter à être un ensemble de bonnes fonctionnalités.
Il sest également attardé sur les décisions majeures qui ont été prises dans la conception du langage et a indiqué sur une ligne du temps leur impact sur la façon de programmer des développeurs.
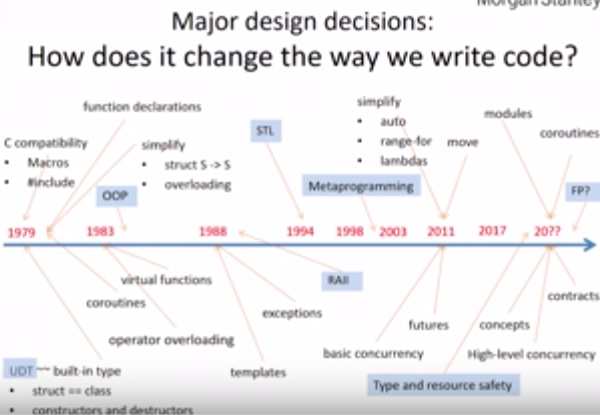
Il a expliqué que, pour sa part, les fonctionnalités majeures sont celles qui changent la façon dont les gens pensent le code, tout comme les concepts, qui devraient arriver dans la prochaine version de C++. Il a néanmoins indiqué quune combinaison de fonctionnalités mineures peut avoir un impact majeur.
À la question de savoir ce qui fait une bonne extension, il explique que les réponses sont très variées. Du point de vue des développeurs, une bonne extension « aide les gens comme moi et mon projet » :
- elle résout des problèmes spécifiques ;
- elle ne nécessite pas de lecture fastidieuses de mode demploi ;
- elle isole le changement ;
- elle nentraîne pas de plantage.
Les difficultés rencontrés par les développeurs lors de la conception dune extension sont :
- un manque dexpérience dans la planification à long terme ;
- des objectifs très souvent définis par dautres personnes ;
- une évaluation des conséquences sur le court terme.
Du point de vue des concepteurs, une bonne extension « va aider de façon significative la communauté des utilisateurs pendant la prochaine décennie » :
- elle répond à un problème général / fondamental ;
- elle fait que le langage est utilisé de façon plus régulière et facilement ;
- elle améliore la réputation de C++.
Malgré tout, il a reconnu que toutes les extensions font plus ou moins de mal :
- elles rendent obsolètes certains supports dapprentissages ;
- elles peuvent avoir un faible ratio bénéfice / coût ;
- elles pourraient ne venir en aide quà une portion de la communauté ;
- elles pourraient induire des coûts à des personnes qui ne les utilisent pas ;
- elles pourraient être une entrave pour les efforts de pratique de programmation.
Tous ces critères ont aidé à façonner C++17. Ainsi, des modifications dont les effets sont relativement isolés ont été acceptées sans problème, comme de simples variables globales, c'est-à-dire la syntaxe inline int x = f();. Au contraire, la convention d'appel unifiée a été rejetée : elle proposait que l'écriture f(x) soit équivalente à x.f() dans tous les cas.
Dans son intervention, il évoque de nombreux points intéressants relatifs à l'évolution de C++.
Source : YouTube
Voir aussi :
 CppCon : Bjarne Stroustrup annonce le projet C++ Core Guidelines, pour aider les développeurs à utiliser le C++ moderne de façon plus efficace
CppCon : Bjarne Stroustrup annonce le projet C++ Core Guidelines, pour aider les développeurs à utiliser le C++ moderne de façon plus efficace
Vous avez lu gratuitement 8 240 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.



